Voiceover:
见者有缘,缘来好运。欢迎访问我们的八股小站JavaU8G————Java_Useful_8股_Guide🎉🎉🎉
🚀 项目简介
本项目
Java_Useful_8股文_Guide致力于打造一个全面且实用的Java技术与面试指南,涵盖了从Java基础知识到高级实践应用的广泛领域,包括但不限于Java面试、算法、JavaSE、并发编程、JVM优化、MySQL、OS、中间件、微服务等核心知识点,以及Spring全家桶及设计模式等内容。
🎵 互动式学习体验
我们的知识库网站独具匠心地集成了音乐播放器功能,让学习者能够在一首歌的时间内专注于并掌握一个Java知识点。这一创新的学习模式旨在提升学习效率与乐趣,让您在轻松的旋律中深入理解Java技术栈的关键概念。开启“
听歌学Java”的高效之旅。阅读
Java_Useful_8股文_Guide详尽内容的同时,将理论知识与实践相结合,实现全方位、多感官的学习体验。无论您是在复习Java基础,还是在钻研JVM调优的复杂细节,都有相应的精选歌曲陪伴您的学习之路。欢迎广大开发者积极参与,亲身参与到这种新颖的学习方式之中,共同打造更为生动和实用的Java面试及技术提升资源!
📚 主要内容(Plan)
JavaSE:深入浅出地讲解Java语言的基础概念与进阶特性。JUC:收录大量并发实例代码及分析,帮助你掌握多线程开发技巧。JVM:提供详尽的JVM原理介绍与实际调优案例,助你成为JVM调优专家。DesignPatterns:总结常用的设计模式及其应用场景,提升你的软件设计能力。SpringFrames:全面解读Spring家族各组件及其实战用法,增强你在企业级开发中的竞争力。JavaInterview:汇总各类Java面试题目的解析与讨论,为你准备面试保驾护航。
🔍 网站地址
🌱 更新维护
为了持续提供优质内容,本项目将坚持每日或每周定期更新,及时跟进最新的
Java技术和面试趋势。我们也诚挚邀请社区成员参与贡献,通过
Pull Request(PR)的方式分享您的知识和经验。
🌟 互动与参与
欢迎各位开发者关注此项目、点赞
Star以示支持,并积极参与讨论与共建。让我们携手为Java开发者社群创造一份高质量、持续更新的知识宝典!如何参与?
- 点击右上角的
Github按钮关注项目进展;- 通过
Fork功能复制项目到自己的GitHub账户,对内容进行修改后发起Pull Request;- 在
Issues区域提出问题、建议或者分享新的面试题目与解析。
更新Timeline_2024_04
更新Timeline_2024_03
| ID | TITLE | UPDATE_TIME | AUTHOR |
|---|---|---|---|
| 4 | e签宝24春招笔试 | 03-09 18:40 | WL2O2O |
| 3 | 汉得24春招Java研发第一批 | 03-09 18:40 | WL2O2O |
| 2 | 美团24春招软开(到店业务) | 03-09 18:26 | WL2O2O |
| 1 | 链表 | 03-02 14:36 | WL2O2O |
更新Timeline_2024_01
| ID | TITLE | UPDATE_TIME | AUTHOR |
|---|---|---|---|
| 6 | Linux用过什么命令 | 01-10 16:15 | WL2O2O |
| 5 | 专科应届-软通动力一面 | 01-10 16:02 | WL2O2O |
| 4 | 介绍一下RabbitMQ | 01-07 09:02 | WL2O2O |
| 3 | 介绍一下ThreadLocal | 01-07 08:49 | WL2O2O |
| 2 | BIO、NIO、AIO? | 01-03 09:42 | WL2O2O |
| 1 | 什么是微服务 | 01-01 17:42 | WL2O2O |
更新Timeline_2023_12
| ID | TITLE | UPDATE_TIME | AUTHOR |
|---|---|---|---|
| 32 | 介绍一下ThreadLocal | 12-30 10:00 | WL2O2O |
| 31 | 说说你对HashMap数据结构的理解 | 12-30 09:31 | WL2O2O |
| 30 | 说说String、StringBuilder和StringBuffer | 12-29 13:17 | WL2O2O |
| 29 | 介绍一下JDK、JRE和JVM | 12-28 09:15 | WL2O2O |
| 28 | 你了解校招? | 12-27 22:00 | WL2O2O |
| 27 | 介绍一下AOP | 12-25 10:49 | WL2O2O |
| 26 | 介绍一下IOC | 12-25 10:49 | WL2O2O |
| 25 | 算法笔记 | 12-23 23:34 | li-zixin |
| 24 | 设计模式有哪些原则 | 12-23 20:31 | WL2O2O |
| 23 | Java中有哪些设计模式 | 12-23 20:23 | WL2O2O |
| 22 | MyISAM和InNoDB存储引擎的区别 | 12-23 10:07 | WL2O2O |
| 21 | 什么是关系型数据库与非关系型数据库 | 12-23 09:40 | WL2O2O |
| 20 | JVM的内存区域是怎么划分的 | 12-23 08:02 | WL2O2O |
| 19 | 视频资源 | 12-20 21:50 | WL2O2O |
| 18 | 算法资源 | 12-20 21:38 | WL2O2O |
| 17 | 什么是设计模式 | 12-20 11:29 | WL2O2O |
| 16 | JVM的类加载过程是怎么样的 | 12-18 14:06 | WL2O2O |
| 15 | 我的算法小抄 | 12-18 14:01 | WL2O2O |
| 14 | 创建Java对象有几种方式 | 12-16 08:58 | WL2O2O |
| 13 | 什么是多态,你是怎么理解的 | 12-14 10:57 | WL2O2O |
| 12 | 介绍一下Java语言 | 12-14 08:57 | WL2O2O |
| 11 | 用过哪些注解 | 12-13 16:37 | WL2O2O |
| 10 | Spring和SpringBoot的区别 | 12-13 16:00 | WL2O2O |
| 9 | ArrayList与LinkedList的区别 | 12-12 20:16 | WL2O2O |
| 8 | 郑州向前 | 12-10 | feiChao33 |
| 7 | 岐飞科技 | 12-10 | Myming621 |
| 6 | 北京小羊驼 | 12-10 | Myming621 |
| 5 | 牧原科技 | 12-10 | WL2O2O |
| 4 | 郑州乐精灵 | 12-7 | WL2O2O |
| 3 | 鑫丽锋科技 | 12-7 | WL2O2O |
| 2 | MySQL常考自检 | 12-7 | WL2O2O |
| 1 | Java SE | 12-7 | WL2O2O |
Java概述
什么是 Java 语言?
Java 语言是一门面向对象的编程语言,不仅吸收了 C++ 语言的各种优点,还舍弃了 C++ 中难以理解的多继承以及指针的概念,因此 Java 语言功能强大且简单易用。Java 语言很好的实现了面向对象的思想,因此支持我们以优雅的思维方式进行复杂的编程。
Java 语言的特点?
- 面向对象
- 平台无关
- 编译与解释并行
- 支持多线程
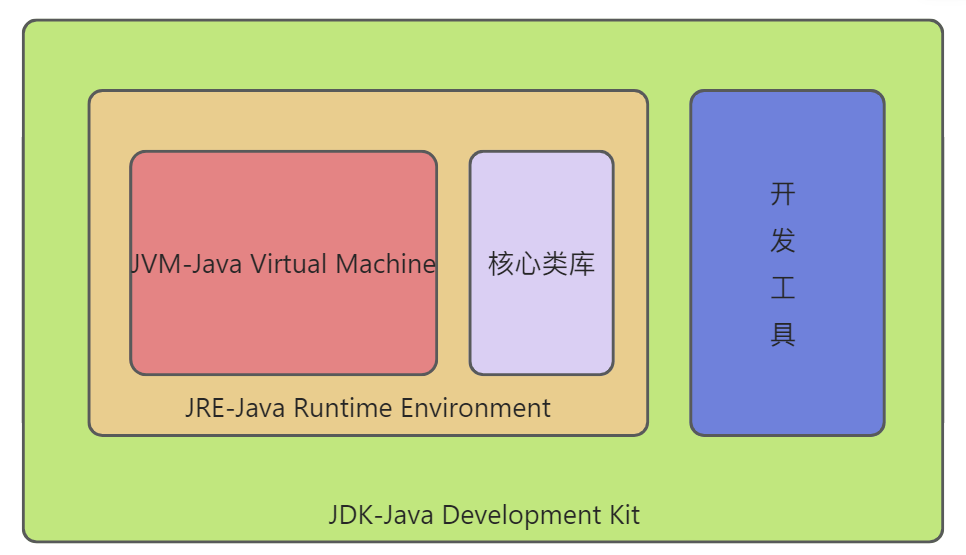
JVM、JDK、JRE?
JVM -- Java 虚拟机 JRK -- Java 开发工具包 JRE -- Java 运行环境
三者之间的关系是:JDK > JRE > JVM
Java基础
- Java有几种数据类型?分别是哪些?
- 怎么理解
&和&& - 自增运算是怎么理解的?
int i = 1;
i = i++;
System.out.println(i);
面向对象
- 什么是面向对象?有哪些特性?
- 什么是多态?怎么理解多态?
什么是多态?
多态就是,对于同一个父类,指向不同子类对象的同一个行为,运行出来结果不同。
怎么理解多态?
例如伪代码:
class Animals {
public void sleep() {
sout("坐着睡!");
}
}
class Dog extends Animals {
@Override
public void sleep() {
sout("站立着睡!");
}
}
class Cat extends Animals {
@Override
public void sleep() {
sout("睁眼睡!");
}
}
// 同一个父类 Animals,指向不同子类 Dog、Cat
Animals animals1 = new Dog();
Animals animals2 = new Cat();
对于animals1.sleep()和animals2.sleep(),最后运行出来可能会有不用的结果,但是这取决于几个条件:
-
继承类或实现接口
-
子类重写方法
-
同一个父类,指向不同子类
重载与重写什么区别?
引用 Wiki 百科:
函数重载规则
- 多个函数定义使用相同的函数名称
- 函数参数的数量或类型必须有区别
函数重载是静态多态的一种类别,其使用某种“最佳匹配”算法解析函数调用,通过找到形式参数类型与实际参数类型的最佳匹配来解析要调用的具体函数。该算法的细节因语言而异。
函数重载通常与静态类型编程语言(在函数调用中强制执行类型检查)有关。重载函数实际上只是一组具有相同名称的不同函数。具体调用使用哪个函数是在编译期决定的。
在 Java 中,函数重载也被称为编译时多态和静态多态。
因此我们大概明白:
- 重载是编译时重载的,编译时根据参数,决定调用哪个方法
- 重写是运行期重写的,运行时根据父类指向的子类,调用方法
总结:
重载和重写都是多态的体现,维基百科中也有说明多态分为动态多态和静态多态
如图:

那么我们不妨理解为重载为静态动态(编译器决定)、重写为运行期决定的,为动态多态。
-
==与equals的区别? -
重写过
equals和hashcode吗?为什么要重写? -
解释一下深拷贝和浅拷贝。
- Java创建对象的几种方式?
-
new
-
反射
-
clone
-
序列化
怎么理解反射?
通过new来创建对象就是正射,是在编译时就会确定创建的对象类型;而反射就是动态地获取类信息、构造器进而newInstance创建对象的过程。
怎么通过反射来创建一个对象?
无参实例化:
Object obj = Class.forName(类名).getConstructor().newInstance();
有参实例化:
Object obj = Class.forName(类名).getConstructor(String.class).newInstance("汪汪");
public class Main {
public static void main(String[] args) {
try {
// 获取Dog类的Class对象
Class<?> dogClass = Class.forName("Dog");
// 获取Dog类的构造器
Constructor<?> dogConstructor = dogClass.getConstructor();
// 通过构造器创建Dog对象
Object dog = dogConstructor.newInstance();
// 如果需要初始化参数,可以使用带有参数的构造函数
Constructor<?> dogConstructorWithParams = dogClass.getConstructor(String.class);
Object dogWithName = dogConstructorWithParams.newInstance("旺财");
} catch (ClassNotFoundException | NoSuchMethodException | IllegalAccessException | InstantiationException | InvocationTargetException e) {
e.printStackTrace();
}
}
}
class Dog {
private String name;
public Dog() {
name = "小黄学长";
}
public Dog(String name) {
this.name = name;
}
public String getName() {
return name;
}
}
String
- 说说
String,是基本数据类型吗?
- String、StringBuffer、StringBuilder有什么区别?
区别:
String类是不可变的,StringBuilder和StringBuffer是可变的;StringBuffer是线程安全的
知识扩展:
StringBuffer为什么是线程安全的?
-
了解
intern方法吗? -
String 是如何保持不可变的?(源码 Final 类)
Integer
- String怎么转Integer?原理?
Object
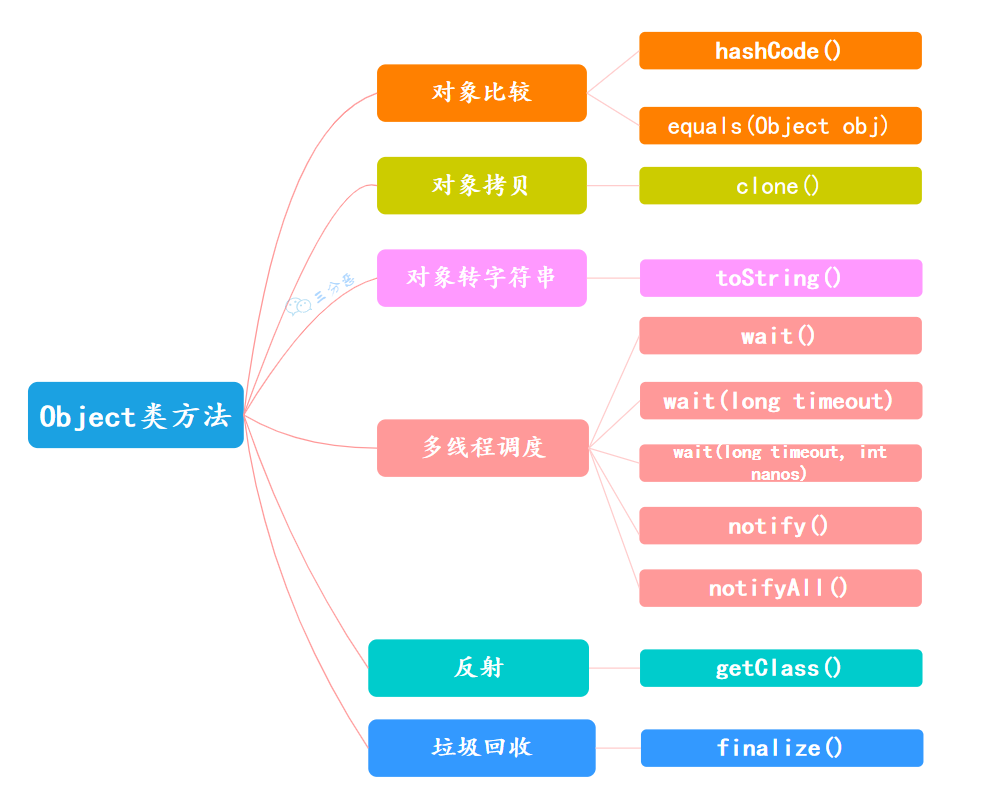
- 了解过
Object类吗?都有什么方法?你怎么理解finalize方法?
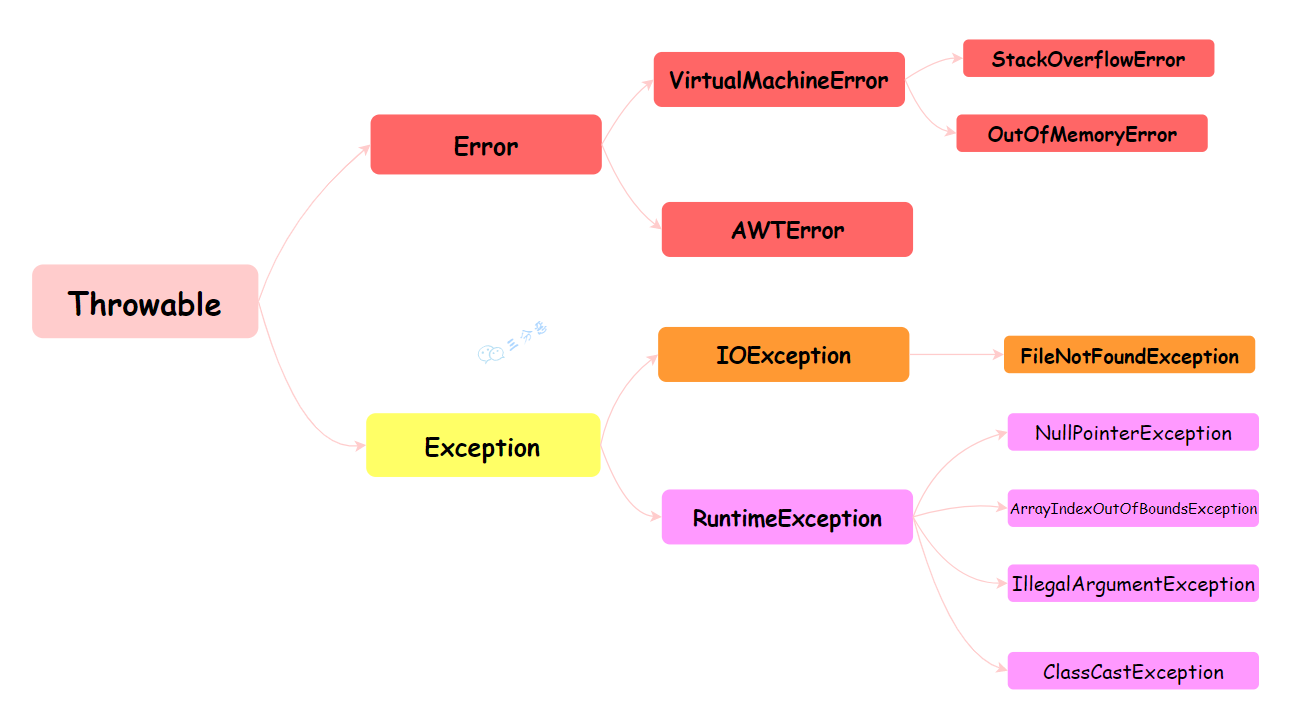
异常处理
- Java中的异常体系
- 怎么处理异常?
- 捕获try{}catch{}finalize{}
- 抛出throw、throws
I/O
| BIO--Blocking IO | 同步阻塞IO(一个连接一个线程,发起请求一直阻塞,一般通过连接池改善) | 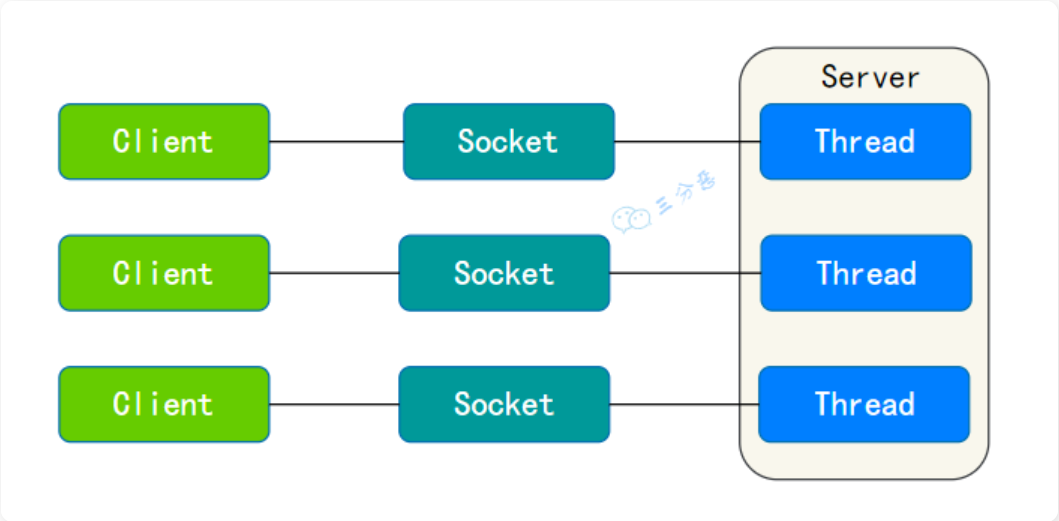 |
|---|---|---|
| NIO--Non-blocking IO | 同步非阻塞IO(多个连接复用一个线程,一个请求一个线程) | 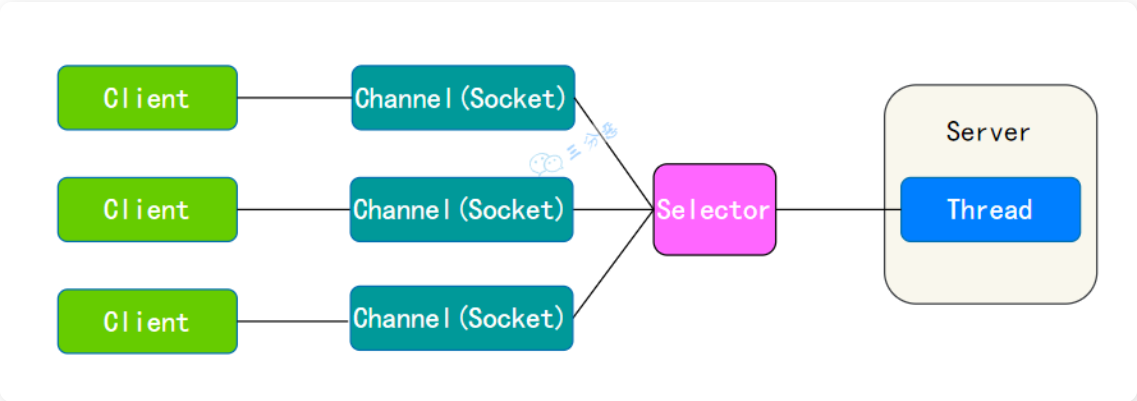 |
| AIO--Asynchronous IO | 异步非阻塞IO(一个有效请求一个线程,IO请求立即返回,操作结束后,回调通知) |  |
- IO流体系结构
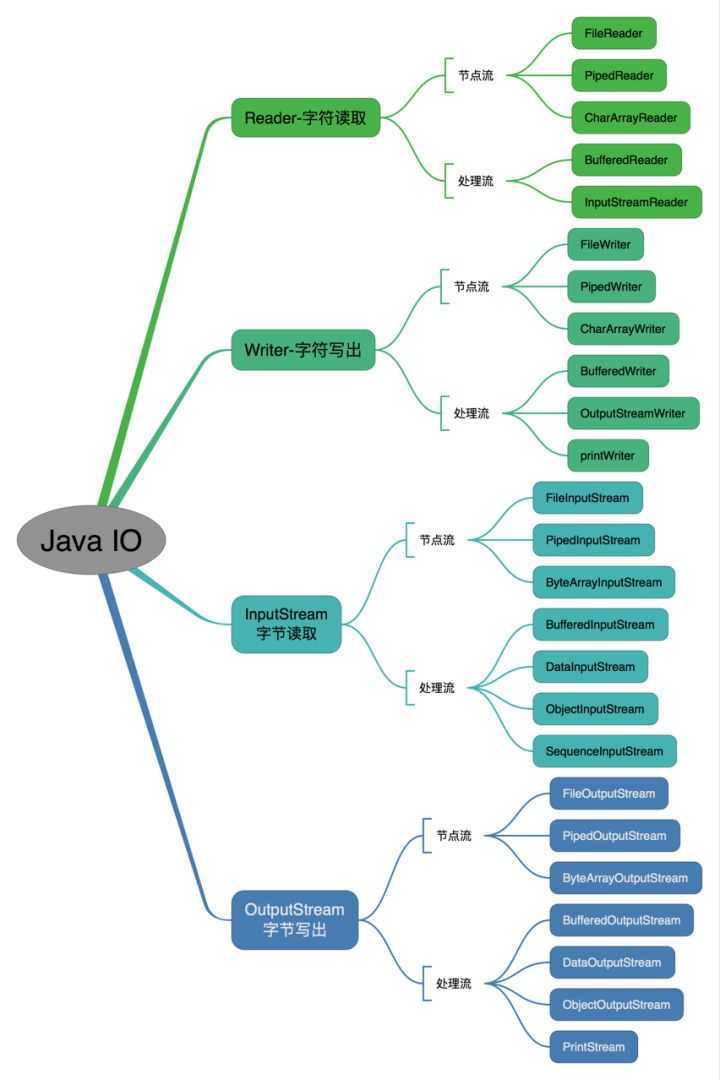
- 什么是装饰器模式?
我对装饰器的理解就是继承,然后增加新功能,但它们的核心区别在于装饰器模式是通过“添加”新的功能,而不是通过“重写”原有功能来实现扩展的。
在IO流中,这种模式被广泛应用。例如,在java.io包中,InputStream和OutputStream是两个基础的输入输出流类,它们定义了输入输出流的基本行为和接口。然后,有许多其他的类和接口继承自InputStream和OutputStream,并添加了新的功能。这些新类可以看作是装饰器,它们可以增强原有类(被装饰类)的功能。例如,BufferedInputStream和BufferedOutputStream可以在原有类的基础上添加缓冲功能,提高IO性能。 总的来说,装饰器模式是一种灵活且强大的设计模式,它允许我们在运行时动态地添加或删除功能,而无需修改原始的类。这种设计模式提高了代码的复用性和可扩展性。 手撸装饰器模式:
public interface Printer {
void print();
}
public class StandardPrinter implements Printer {
@Overvide
public void print() {
System.out.println("Standard print!");
}
}
public class ColorPrinter implements Printer {
private Printer printer;
public ColorPrinter(Printer printer){
this.printer = printer;
}
@Overvide
public void print() {
System.out.print("Color print!");
Printer.print();
}
}
public class Main {
public static void main(String[] args) {
Printer sPrinter = new StandardPrinter();
sPrinter = new ColorPrinter(sPrinter);
sPrinter.print();
}
}
序列化
- 什么是序列化与反序列化
- 序列化有哪几种方式?
- Java对象流序列化
一般会用Java原生IO 进行转化,一般会用ObjectIO
- JSON序列化
JSON序列化的方式有很多,一般会选择使用jackson包中的ObjectMapper类来将Java对象转化为byte数组或将json串转化为对象
- ProtoBuff序列化
是一种轻便高效的结构化数据存储格式,通过其序列化对象可以很大程度的把对象进行压缩,大大减小数据传输大小,提高性能。
泛型
- 什么是泛型?
- 什么是类型擦除?为什么要擦除?
- 为什么泛型不可以被重载?
注解
- 什么是注解?注解的生命周期?
- 说说
@Override和@Autowired的源码
反射
-
怎么理解反射?
-
怎么通过反射来创建一个对象?
源码
- 说说你对
HashMap数据结构的理解?
HashMap数据结构
首先,hashmap 的数据结构是基于数组和链表的,如图:
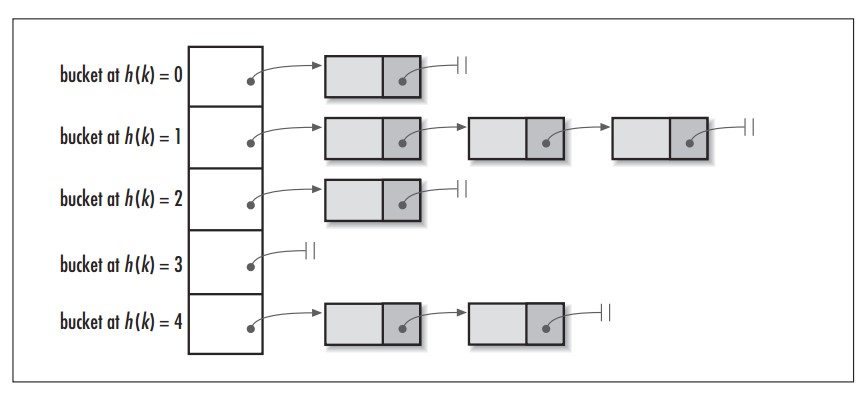
so,既然是基于数组和链表的,那就说明数组和链表的特点也就是 HashMap 的特点:
数组:寻址快,直接根据索引访问元素,插入和删除慢;
链表:寻址慢,需要从头节点开始遍历,插入和删除快。
说到 HashMap 就要说到 Java 8 了,Java 8 之前,HashMap 使用一个数组加链表的结构来存储 【K,V】 键值对。
如果发生 hash 冲突,那么
这将导致在处理 hash 冲突的时候性能不高,尤其是链表很长的时候。因此,Java 8 中的 HashMap 引入了红黑树来替代链表,这样当链表变长的时候,会自动转换为红黑树,从而提高了增删改查的性能。
- 什么是 Hash 冲突?怎么解决?
什么是 Hash 冲突
怎么解决?
- 为什么阿里巴巴Java开发者手册中有一条建议是强制禁止使用构造方法把 BigDecimal(double) 的方式把 double 的值转化为 BigDecimal 对象?
说明:因为会存在精度损失风险,如:BigDecimal(0.1F),实际存储值为0.10000000149,
正确的方法应该怎么做?
一:String入参:BigDecimal bd = new BigDecimal("0.1")
二:使用内部的 valueOf 方法:BigDecimal bd1 = BigDecimal.valueOf(0.1);
基础篇
Q:什么是关系型数据库与非关系型数据库?
A:
关系型数据库
Q:什么是数据库第一二三范式?
A:
- 第一范式:又称专一范式,字段不能再拆分;
- 第二范式:又称 MySQL 家规,必须完全依赖顺从主键,若有与主键无关字段者,设置为联合主键;
- 第三范式:又称恋爱脑范式,遵守家规,远离小三。

一般来说,“小企”这个渣男(也可能不止小企)在日常开发中都是违反范式家规标准的,要为了性能,通过一些冗余的数据,空间换时间。
Q:MySQL 有几种字段类型?
A:字段类型大致可以分为三类:数值类型、字符类型、时间类型
- 数值类型:
- 整数类型:微小TYNYINT、小SMALLINT、中等MEDIUMINT、INT、大整型BIGINT;
- 小数类型:FLOAT、DUBBLE、DECIMAL、NUMERIC
- 字符类型:(还有好几种)
- CHAR
- VARCHAR
- BINARY
- VARBINARY
- BLOB
- 二进制大对象类型,用于存储二进制数据(如文档、图像、音频等),有两个分支,小TINYBLOB和长LONGBLOB
- TEXT
- 文本类型,不许预设长度,可根据需要动态划分空间。也分为 TINYTEXT 和 LONGTEXT,以适应不同大小的文本数据
- ENUM
- 枚举类型,限制了字段存储的值
- SET
- 集合类型,不可重复
- 日期/时间类型
- DATE
- TIME
- DATETIME
- TIMESTAMP
Q:CHAR 和 VARCHAR 字符类型的区别?
A:
char长度固定,所以存取速度快,甚至快varchar一半;如果长度没有达到预设值,用空格补充。因为定长,所以浪费一些空间,属于空间换时间。最多可存255个字符;varchar字符长度可变,所以不浪费空间,属于时间换空间。最多可存放65532个字符串,至于为什么是65532,那就需要看相关存储引擎InnoDB的知识了。
Q:说一说两个时间类型的区别
A:
- 时间起始范围不同,
TIMESTAMP为1970-2028,datetime为1000-9999 - 存储空间不同,
TIMESTAMP存储空间为4字节,DATETIME存储空间为8字节 - 时区,
TIMESTAMP存储时间依赖于时区显示,DATETIME存储时间与时区无关 - 默认值,
TIMESTAMP不为空,后者为空
Q:什么类型可以用于存储二进制数据?
A:blob,Blob常常是数据库中用来存储二进制文件的字段类型。通常用于存储大量的数据,例如音频、视频、图片等文件,由于它们的大小,必须使用特殊的方式来处理(例如:上传、下载或者存放到一个数据库)。
Q:怎么存储
emoji表情?
A:
Q:你了解 SQL 的执行流程吗?
A:为了更加直观,借用三元表达式的语法来描述一条 SQL 执行的流程。
- 首先检查 SQL 是否有执行的权限? 查询结果缓存 :返回报错信息;
- 是否有缓存? 直接返回结果 :检查 SQL 是否有语法错误;
- 语法正确? MySQL 的服务器对语句进行优化,确定执行方案 :
- 确定方案?调用数据库引擎接口,执行方案,返回执行结果。
Q:什么是 DDL 与 DML ?
A:是 DBMS 中的不同类型的语言指令集。
- DDL:database definition language,定义或修改数据库结构的命令,例如:CREAT、ALTER、DROP、TRUNCATE(截断,命令用于快速删除表中的所有数据但不删除表本身。)
- DML:database manipulation language,用于操作数据库中的数据的命令,例如CURD
Q:MySQL 怎么进行优化?
A:
- **索引优化:**基于最经常查询的字段或数据,合理的进行创建索引。例如一个用户表(id, name, email),其中基于 email 查询的语句很多,所以可以在 email 字段上创建一个索引:
CREATE INDEX idx_email ON user(email); - **查询优化:**尽量避免全表扫描、减少表连接的操作。例如
SELECT * FROM user WHERE name = '张三' LIMIT 1; - **数据库设计优化:**根据数据访问模式和业务需求设计数据库结构,如何选择合适的数据类型、如何进行数据规范化、什么时候需要反范式设计?
实际上,一般互联网公司的设计都是反范式的,通过冗余一些数据,避免跨表跨库,利用空间换时间,提高性能。
- **分区:**对于大数据量的表,我们可以使用分区技术提高查询效率。分区就是把大表拆分为一个个小表,减少单次查询数据量,提高单次查询的效率 --> 进而提高效率!
- **硬件和配置优化:**除了 SQL 语句和数据库设计,硬件和 MySQL 的配置也会对性能造成影响。所以我们可以根据服务器的硬件状况和业务需求对MySQL的连接数以及内存使用进行配置。
Q:MySQL 数据类型有哪些?Java 中有哪些字段与之对应?
架构篇
首先,收起你自认为架构篇很难理解的想法,我们还是从 MySQL 是一个房子入手。
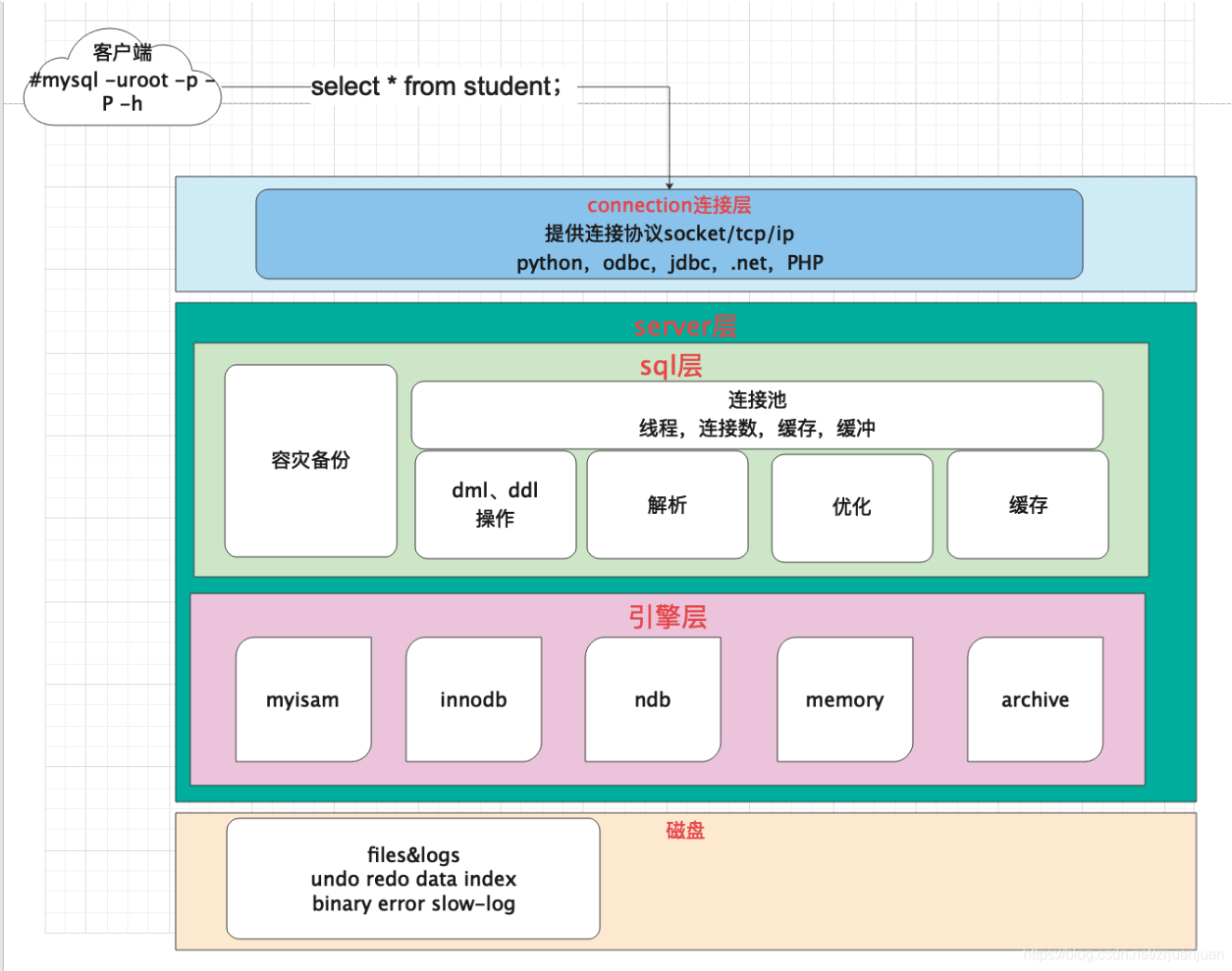
Q:你是怎么理解 MySQL 的架构的?
A:MySQL 就相当于一个档案室,存放不同的档案,一个数据库好用,肯定有原因,架构也就是构成。那么一个快递驿站肯定包括下面这三部分:
- 快递驿站APP--客户端(与用户交互的关键)
- 工作人员--存储引擎(我 MySQL 学的不好,我猜应该是与存储规则相关的)
- 快递货架--服务层(堆放数据,索引数据)
{{{{{{待画图!!!}}}}}} MySQL 逻辑架构图主要分为三层:客户端、存储引擎、服务层
- 客户端层:这是与 MySQL 服务器交互的接口,它提供了用户与服务器进行通信的手段。客户端层处理连接请求、处理查询请求、认证用户权限以及执行与服务器之间的通信。此外,这一层还负责处理与服务相关的各种任务,例如管理连接、处理错误、诊断和调试等。
- Server 层:这一层是 MySQL 的核心,它包含了大多数 MySQL 的服务功能。这包括解析查询语句、分析查询计划、优化查询计划以及执行查询计划等。此外,Server 层还负责处理内置函数,如日期、时间、数学和加密函数等。对于跨存储引擎的功能,如存储过程、触发器和视图等,也都在这一层实现。这些功能对于整个数据库系统来说是至关重要的。
- 存储引擎层:这一层负责数据的存储和提取。存储引擎负责与底层操作系统交互,管理数据的存储位置、文件格式和索引等。不同的存储引擎具有不同的特点和性能,可以根据应用的需求选择适合的存储引擎。MySQL 支持多种存储引擎,如 InnoDB、MyISAM、Memory 等。存储引擎通过 API 与 Server 层进行通信,这些接口屏蔽了不同存储引擎之间的差异,使得上层的应用程序可以透明地访问底层的数据存储方式。
Q:数据库调优,你是怎么做的
A:以下回答来自文心一言,待优化,回答要结合MySQL的架构以及存储引擎来说,以及自己的见解 数据库调优的方法有很多,以下是一些常见的调优方法:
- 定期优化重建数据库:定期对数据库进行优化和重建,可以消除数据库中的碎片和冗余数据,提高数据库的性能和稳定性。
- 减少磁盘写入操作:通过使用缓存技术、优化数据插入和更新操作、避免频繁的磁盘操作等手段,可以减少磁盘的写入操作,提高数据库的性能。
- 合理使用索引:索引是提高查询速度的重要手段,通过添加合适的索引可以加速查询操作。需要根据查询语句和表结构来确定需要添加的索引。
- 优化SQL语句:通过优化SQL语句,可以减少数据库的负载和提高查询效率。例如,避免使用SELECT * 语句,只查询需要的数据字段;避免在查询中使用复杂的子查询和连接查询等。
- 调整数据库参数:根据实际需求和性能测试结果,调整数据库的参数可以提高数据库的性能和响应速度。
- 使用存储过程和触发器:存储过程和触发器可以减少数据库的负载和提高数据处理效率。通过将常用的数据处理逻辑封装到存储过程和触发器中,可以减少对数据库的频繁操作。
- 数据库分区:对于大型数据库,可以采用分区技术将数据分散到不同的磁盘上,提高I/O处理能力和并发性能。
- 使用RAID技术:RAID技术可以提供高性能、高可靠性和高容错的存储系统,通过将数据分散到多个磁盘上,可以提高I/O处理能力和数据安全性。
- 使用缓存技术:缓存技术可以减少磁盘访问次数和提高数据处理速度。例如,使用内存缓存来存储经常访问的数据,减少对磁盘的访问次数。
- 定期备份数据:定期备份数据可以防止数据丢失和灾难性故障,同时也可以提高数据处理效率和安全性。
这些方法可以根据实际情况选择使用,但需要注意的是,数据库调优是一个复杂的过程,需要综合考虑系统硬件、应用程序和数据等方面的因素。因此,在进行数据库调优时,建议根据实际情况进行测试和评估,以确保达到最佳的效果。
Q:你知道三种存储引擎的区别吗?
A:
| 功能 | MlSAM | MEMORY | InnoDB |
|---|---|---|---|
| 存储限制 | 256TB | RAM | 64TB |
| 支持事务 | No | No | Yes |
| 支持全文索引 | Yes | No | Yes |
| 支持树索引 | Yes | Yes | Yes |
| 支持哈希索引 | No | Yes | Yes |
| 支持数据缓存 | No | N/A | Yes |
| 支持外键 | No | No | Yes |
怎么选择存储引擎的使用?
- 想用事务安全,并要求实现并发控制,用InnoDB
- 主要用来查询与插入记录,用MyISAM
- 临时存放数据,不考虑安全,用MEMORY
tips:存储引擎是基于数据表的,所以一个数据库的多个表可以根据实际业务,来使用不同的存储引擎,以此提高整个数据库的性能。
| 区别 | MyISAM | InnoDB |
|---|---|---|
| 存储结构 | 每个表存储成3个文件: | |
| 表定义文件(.frm) | ||
| 数据文件(.MYD) | ||
| 索引文件(.MYI) | 所有表存放于同一数据文件,也可能多个文件或者独立的表空间文件,表的大小一般为2G | |
| 事务 | 不支持 | 支持 |
| 最小锁粒度 | 表级锁,更新会锁表,导致其他查询与插入阻塞 | 行级锁 |
| 索引类型 | 非聚簇索引,B树 | 聚簇索引,B+树 |
| 主键 | 可无 | 如未设置,自动生成(用户不可见) |
| 外键 | 不支持 | 支持 |
| 表行数 | 存有缓存,直接取出 | 需要遍历整个表 |
🆗架构篇就到这里,有没发现,似乎MySQL的基础架构也就这回事,也没啥难点。最后强调一点,当我们试图学会一门知识的时候,不要机械记忆,重要的是融会贯通(内心OS:啥子贯通?不就是理论翻译成人话吗?),找到适合自己记忆的方法。
欢迎来到基础篇😎😎😎
Java基础
什么是 Java 语言?
Java 语言是一门面向对象的编程语言,不仅吸收了 C++ 语言的各种优点,还舍弃了 C++ 中难以理解的多继承以及指针的概念,因此 Java 语言功能强大且简单易用。Java 语言很好的实现了面向对象的思想,因此支持我们以优雅的思维方式进行复杂的编程。
Java 语言的特点?
- 面向对象
- 平台无关
- 编译与解释并行
- 支持多线程
Java创建对象的几种方式?
-
new
-
反射
-
clone
-
序列化
怎么理解反射?
通过new来创建对象就是正射,是在编译时就会确定创建的对象类型;而反射就是动态地获取类信息、构造器进而newInstance创建对象的过程。
怎么通过反射来创建一个对象?
无参实例化:
Object obj = Class.forName(类名).getConstructor().newInstance();
有参实例化:
Object obj = Class.forName(类名).getConstructor(String.class).newInstance("汪汪");
public class Main {
public static void main(String[] args) {
try {
// 获取Dog类的Class对象
Class<?> dogClass = Class.forName("Dog");
// 获取Dog类的构造器
Constructor<?> dogConstructor = dogClass.getConstructor();
// 通过构造器创建Dog对象
Object dog = dogConstructor.newInstance();
// 如果需要初始化参数,可以使用带有参数的构造函数
Constructor<?> dogConstructorWithParams = dogClass.getConstructor(String.class);
Object dogWithName = dogConstructorWithParams.newInstance("旺财");
} catch (ClassNotFoundException | NoSuchMethodException | IllegalAccessException | InstantiationException | InvocationTargetException e) {
e.printStackTrace();
}
}
}
class Dog {
private String name;
public Dog() {
name = "小黄学长";
}
public Dog(String name) {
this.name = name;
}
public String getName() {
return name;
}
}
什么是多态?
多态就是,对于同一个父类,指向不同子类对象的同一个行为,运行出来结果不同。
例如伪代码:
class Animals {
public void sleep() {
sout("坐着睡!");
}
}
class Dog extends Animals {
@Override
public void sleep() {
sout("站立着睡!");
}
}
class Cat extends Animals {
@Override
public void sleep() {
sout("睁眼睡!");
}
}
// 同一个父类 Animals,指向不同子类 Dog、Cat
Animals animals1 = new Dog();
Animals animals2 = new Cat();
对于animals1.sleep()和animals2.sleep(),最后运行出来可能会有不用的结果,但是这取决于几个条件:
-
继承类或实现接口
-
子类重写方法
-
同一个父类,指向不同子类
重载与重写什么区别?
引用 Wiki 百科:
函数重载规则
- 多个函数定义使用相同的函数名称
- 函数参数的数量或类型必须有区别
函数重载是静态多态的一种类别,其使用某种“最佳匹配”算法解析函数调用,通过找到形式参数类型与实际参数类型的最佳匹配来解析要调用的具体函数。该算法的细节因语言而异。
函数重载通常与静态类型编程语言(在函数调用中强制执行类型检查)有关。重载函数实际上只是一组具有相同名称的不同函数。具体调用使用哪个函数是在编译期决定的。
在 Java 中,函数重载也被称为编译时多态和静态多态。
因此我们大概明白:
- 重载是编译时重载的,编译时根据参数,决定调用哪个方法
- 重写是运行期重写的,运行时根据父类指向的子类,调用方法
总结:
重载和重写都是多态的体现,维基百科中也有说明多态分为动态多态和静态多态
如图:
那么我们不妨理解为重载为静态动态(编译器决定)、重写为运行期决定的,为动态多态。
介绍一下String、StringBuilder和StringBuffer
对比之类的问题,要先说区别
String类是不可变的,StringBuffer和StringBuilder是可变的;String和StringBuffer是线程安全的,StringBuilder是非安全的;
知识扩展:
-
String为什么不可变?因为我们通过源码可以看出,
String类是通过final关键字来修饰的,这就意味着他不能够被继承,不能被重写方法,所以是不可变的。 那么为什么我们平时用到的concat、trim等等方法,不都改变了String的值了吗? 其实不然,我们虽然改变了其值,但是其实是创建了一个新的对象,并没有改变其值。 -
StringBuffer为什么是线程安全的?StringBuffer和StringBuilder很类似,最大的区别就在于StringBuffer是线程安全的,由源码中StringBuffer中的
append方法源码修饰符synchronized足以看出该方法是线程安全的。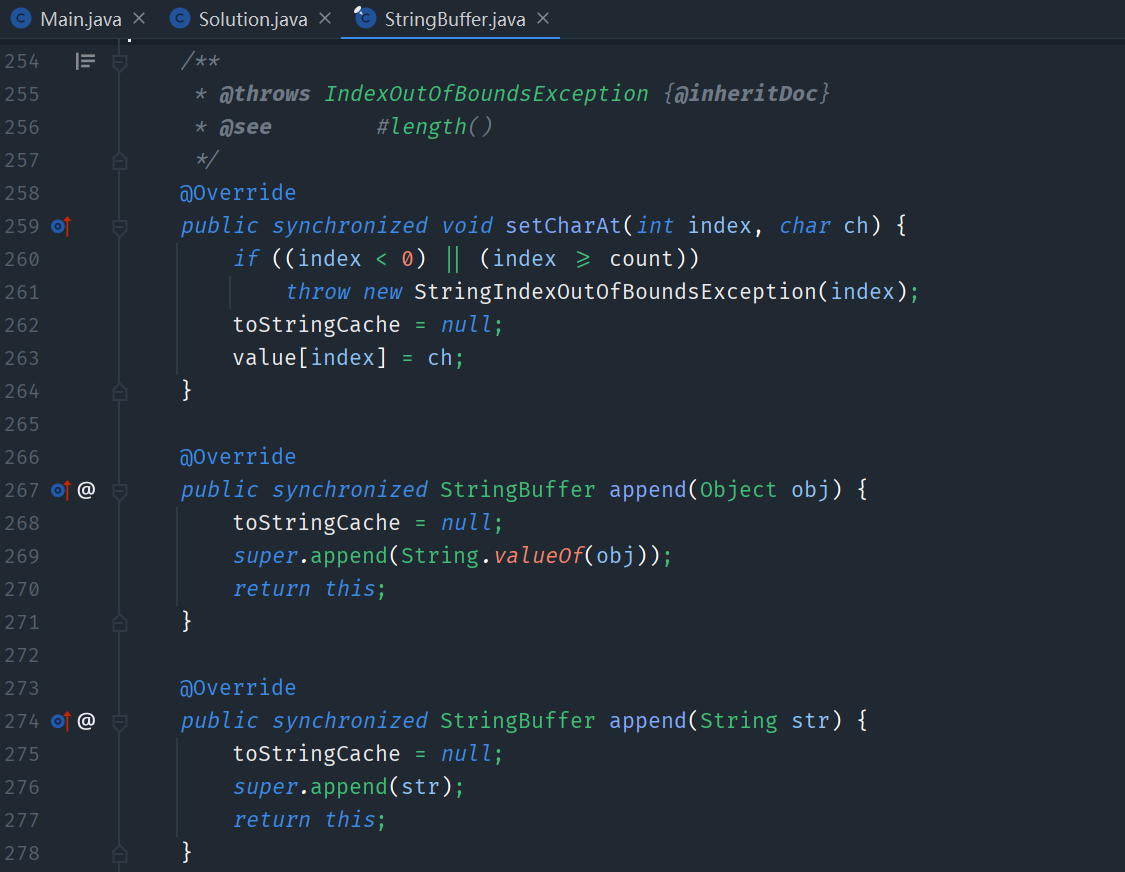
什么是 BIO、NIO、AIO
| BIO--Blocking IO | 同步阻塞IO(一个连接一个线程,发起请求一直阻塞,一般通过连接池改善) | |
|---|---|---|
| NIO--Non-blocking IO | 同步非阻塞IO(多个连接复用一个线程,一个请求一个线程) | |
| AIO--Asynchronous IO | 异步非阻塞IO(一个有效请求一个线程,IO请求立即返回,操作结束后,回调通知) | |
先看维基百科
怎么理解
BIO、NIO、AIO
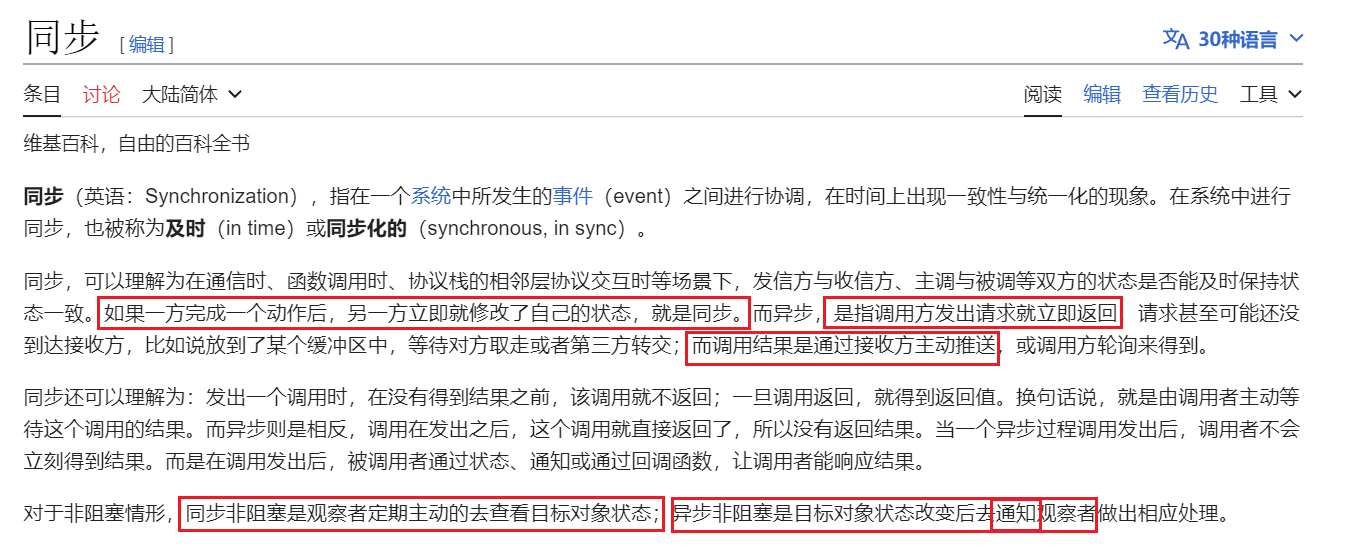
我的理解
同步阻塞与同步非阻塞的区别,我们举个例子来说明: 同步阻塞:鲁智深排队(阻塞)打酒,时不时问小二,等着酒(同步)被盛好; 异步阻塞:鲁智深排队(阻塞)打酒,等着叫号机器或者大屏通知(异步)响应; 同步不阻塞:鲁智深酒馆打酒,坐着玩手机(不阻塞),时不时问小二,等着酒(同步)被盛好; 异步不阻塞:鲁智深酒馆打酒,坐着玩手机(不阻塞),等着叫号机器或者大屏通知(异步)响应
同步与异步的区别在于 同步:请求与响应同时进行,直到响应再返回结果; 异步:请求直接返回空结果,不会立即响应,但一定会有响应,通过通知(叫号机)、状态(大屏通知)、回调函数响应
阻塞与非阻塞的区别在于 阻塞:请求后一直等待 非阻塞:请求后,可以继续干其他事,直到响应
知识扩展
- IO流体系结构
欢迎来到数据库篇😎😎😎
MySQL
什么是关系型数据库与非关系型数据库
维基百科介绍

我的理解
- 常见的关系型数据库有
MySQL和Oracle等,关系型数据库就是采用了一种关系模型的数据库。- 这个关系模型通常可以理解为表格的行与列
- 非关系型数据库就是
NOSQL数据库,有Redis和MongoDB等。- 这个关系模型通常可以理解为键值对存储
二者的特点与区别
-
🤖传统关系型数据库的数据是以行列的方式进行存储的,
👾非关系型数据库以键值对的形式存储
-
🤖关系型数据库的数据通常是存储于硬盘的,
👾非关系型数据库基于内存
-
🤖关系型数据库强调数据的读写一致性,不惜降低读写性能,
👾非关系型数据库不强调
-
🤖强调事务的
ACID原则,即原子性(Atomatic)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)👾
-
🤖关系型数据库采用结构化查询语言,
👾非关系型数据库采用根据
Key进行查询
区别
| 关系型数据库 | 非关系型数据库 | |
|---|---|---|
| 代表语言 | MySQL、Oracle | Redis、MongoDB |
| 存储形式 | 通常是基于硬盘(有内存表) | 通常基于内存 |
| 查询方式 | 结构化查询 | 根据Key查询 |
| 强调事务 | 强调 | 不强调 |
知识扩展
那么还有什么模型的数据库呢?
- 键值型————
Redis - 文档型————
MongoDB - 向量型————例如腾讯自研的向量数据库
- ·······
MySQL有几种存储引擎?
- MyISAM
- InNoDB
- MEMORY
- ······
MyISAM和InNoDB有什么区别
维基百科介绍

我的理解
MyISAM与InNoDB的分界点在于MySQL的5.5版本,5.5之后,随着不断追求高并发与事务,就逐渐取代了MyISAM存储引擎。
| MyISAM | InNoDB | |
|---|---|---|
| 事务 | 🚫 | ✔️ |
| 索引 | 非聚焦索引 | 聚焦索引 |
| 外键 | 🚫 | ✔️ |
| 最小粒度 | 表锁 | 行锁 |
| 行数 | 保存,可直接读取 | 不保存,需要count |
MySQL有几种存储引擎?
- MyISAM
- InNoDB
- MEMORY
- ······
欢迎来到集合篇😎😎😎
Java 集合
ArrayList与LinkedList的区别
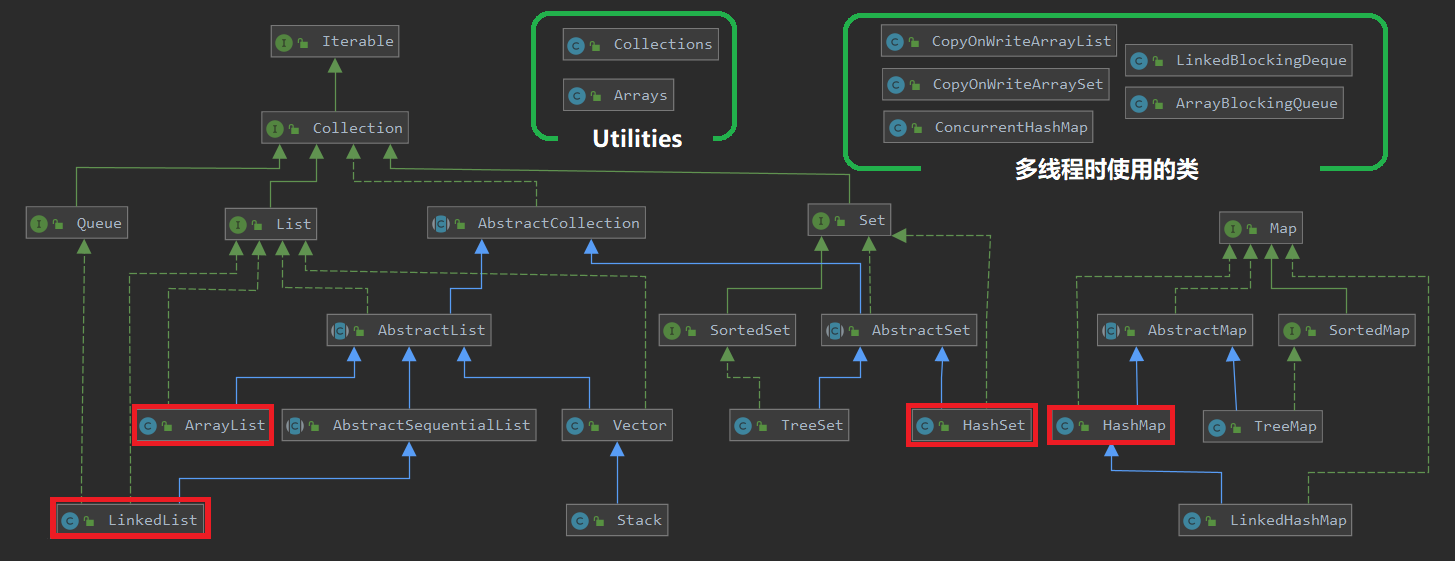
首先,他们都是List的集合的实现方式之一。具体来说,集合List有ArrayList、LinkedList、AbstractList、Vector四种实现方式,因为实现方式的不同,所以效率也不同。其中LinkedList些许特别,具体看图。(留一个小问题:LinkedList可以实现队列与栈吗?)
如果说二者处理数据的效率区别的话,如果数据和运算量很小的情况下,那么就没有什么对比意义了,如果数据量很大,那么有着以下区别:
ArrayList底层是一个数组,因此它可以直接基于索引访问元素,查找和修改效率高,增加删除的话,如果是对于中间元素,则需要移动大量元素,那么效率低。当更多元素添加进来,其容量大小会动态增长,因为是基于数组的,所以内部元素可以通过get()与set()方法进行访问。
扩容策略:
- 初始默认容量
10时,检查新增元素之后,是否超过数组容量,超过则扩容(检查容量)- 在
JDK 7之前,容量增加为原来的两倍,但最多不超过Integer.MAX_VALUE即2^32 - 1。JDK 7之后,增加为原来的1.5倍,即newCapacity=oldCapacity+(oldCapacity >> 1),其实JDK 8中ArrayList的最大容量为Integer.MAX_VALUE - 8,是因为内部使用了数组复制的技巧对空间和内存做了优化,需要 8 个元素的空间。(设置新容量的数组)- 将旧数组的元素复制到扩容后的新数组中(复制数组)
建议:
因为
ArrayList的初始容量很小,所以如果能预估数据量的话,尽量分配一个合理的初实容量,这样可以极大减少数据扩容的开销
-
LinkedList底层是一个双向链表,因此当增加或者删除一个元素时,通过直接移动指针的指向就能实现,增删效率高,但是对于查找或修改(也就是get()与set()),它需要从头结点遍历元素,因此效率低。-
LinkedList怎么实现队列与栈? 通过上图我们可以看到,因为
LinkedList继承于一个AbstractSqquentiaList的双向链表,然后就决定了它可以调用push()和pop()方法来当作栈使用;又因为LinkedList实现了List接口,所以可以调用里面的add()和remove()方法进行实现队列的操作。
-
说说你对 HashMap 数据结构的理解
欢迎来到进阶篇😎😎😎
Java多线程高并发
什么是ThreadLocal?
维基百科
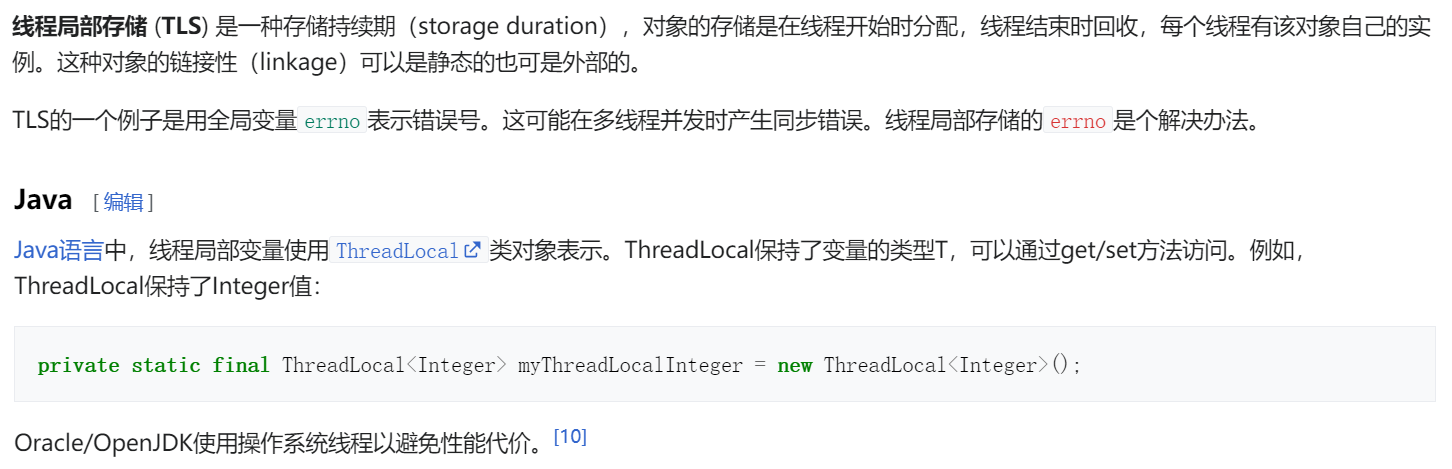
我的理解
ThreadLocal是java.lang下面的一个类,是用来解决多线程中的并发问题。实际上它就是一个线程内的一个局部变量。比如可以存放一些线程安全的相关变量,用于线程内共享,线程之间互斥。这样其他线程进行访问,发现与变量中存放的信息不一致,于是就达到了解决并发的问题。
ThreadLocal中的四个方法:
- initValue
- get
- set
- remove
应用场景
-
用户信息存储
在项目中的大多时候,都需要对用户进行鉴权,此时,我们可以将用户的信息放在
ThreadLocal中,有需要时取,很方便! -
线程安全
由于
ThreadLocal的隔离特性,加上一些并发安全处理的变量并不是线程安全的,所以,我们可以把这些变量配合它进行使用,这样就达到了线程安全的目的。 例如:SimpleDataFormat变量。 -
PageHelper分页
这个是
MyBatis提供的分页插件。我们在代码中设置的分页参数、页码、页大小的信息都会存储于ThreadLocal中,方便执行分页对其进行读取。 -
日志上下文存储
-
traceid存储
-
数据库Session
总结
主要就是两个作用:
- 线程安全
- 进程内读取、传递信息
欢迎来到 JVM 篇😎😎😎
JVM
JVM的内存区域是怎么划分的
我们通过JVM的官网虚拟机规范定义可知,JVM的运行时内存区域主要是由Java堆、虚拟机栈、本地方法栈、方法区以及程序计数器和运行时常量池组成的。其中,堆、方法区与运行时常量池是线程共享的区域。
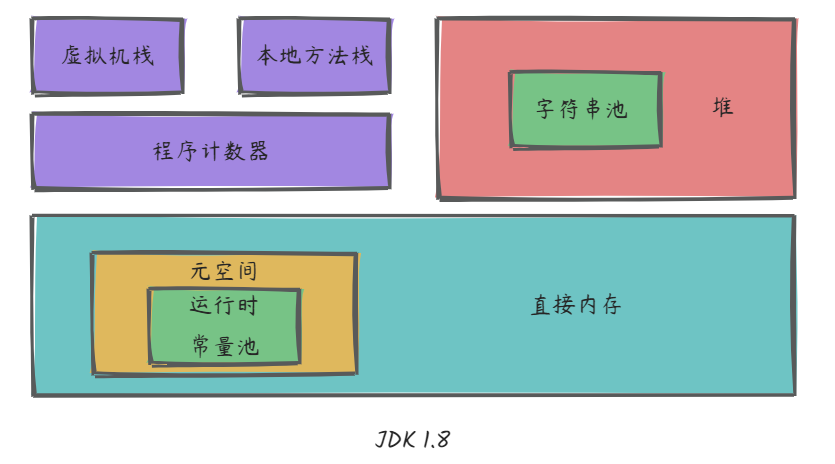
虚拟机栈:用于存储Java中的局部变量。生命周期:方法调用-->创建栈帧-->存储局部变量、操作数栈、动态链接、方法出口等-->弹出栈帧-->结束
本地方法栈:特殊的栈。类似于Java虚拟机栈,但是支持本地方法的执行
程序计数器:
Java堆:
方法区:
运行时常量池:
JVM 的类加载过程?
Java 中的类加载过过程分为三个阶段:
- 加载
- 链接
- 验证
- 准备
- 解析
- 初始化
这三个阶段怎么理解?
-
加载阶段: 查找并加载类的二进制数据(网络、jar 包、运行时生成等)。将类的
.class文件中的二进制数据读入内存当中。将其放在方法区中,然后创建一个java.lang.Class对象(存放于堆中)用于封装类在方法区的数据结构。 -
链接阶段: Java 类加载器对类进行验证、准备(分配内存、初始化默认值)和解析操作,将类与类之间的关系确定好(符号引用转直接引用),然后校验字节码。
- 验证:验证文件格式、元数据、字节码、二进制兼容性是否正确
- 准备:给类的静态变量分配内存,初始化为默认值。
- 解析:把类的符号引用转为直接引用
-
初始化阶段: 类加载过程的最后一步,初始化阶段是执行类构造器中
<clinit> ()方法的过程。这里利用了一种懒加载的思想,所有 Java 虚拟机实现必须在每个类或者接口被 Java 程序首次主动使用才初始化。
知识扩展
什么是符号引用和直接引用?
符号引用: 是一种直接表示引用目标的符号名称。例如:类名、字段名、方法名等。符号引用和实际的内存地址无关,符号引用只是一个标识符。用于描述被引用者,也就是类似于变量名的东西。符号引用产生于编译期,存储于Class文件。
直接引用: 是实际指向目标的内存地址。例如:类的实例、方法的字节码等。直接引用与内存地址直接相关,产生于运行期。
说白了,符号引用就相当于一个变量名;直接引用就相当于内存地址。
我的理解
JDK、JRE、JVM三者关系?
JDK--Java开发工具包,是一个功能齐全的开发SDK,具有编译器(javac)和工具(javadoc、jdb)功能,可以创建和编译程序。- ``JRE
--Java运行时环境,用于运行已经编译的Java程序(.class)所需要的内容集合,包括JVM以及Java`核心类库或者其他构件,他只是运行环境,并不能创建程序。 JVM--Java虚拟机,Java程序运行于Java虚拟机中,针对不同的系统实现,因此Java语言可以实现跨平台
三者之间的关系是:JDK > JRE > JVM
知识扩展
什么是字节码?为什么从编译到执行还要多一个字节码文件?
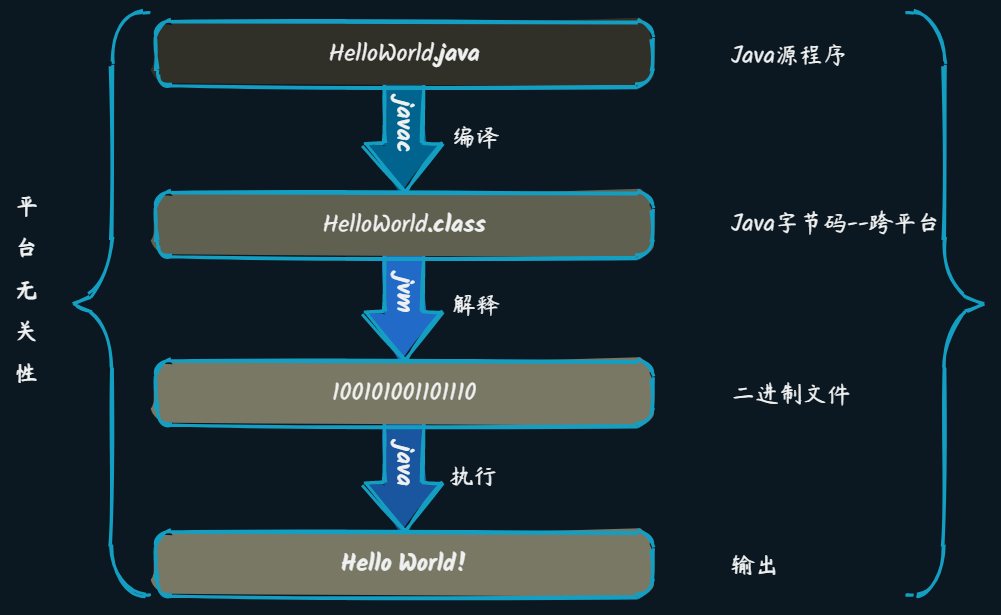
字节码是经过Java编译之后的字节码文件,是实现跨平台的关键。
所谓平台无关性呢,指的就是在不同的操作系统之间运行不受限制,一次编译,到处执行(Write once, Run anywhere)。
但是针对不同的硬件和操作系统来说,平台之间比如说二进制指令还是有区别的,所以此时就体现出了JVM的作用。不同的平台下载相应的JVM,JVM对字节码文件进行解释成对应平台的二进制文件,这样就解决了不同平台的二进制指令不同,然后就可以实现跨平台运行了。所以字节码文件在此提现了关键性的作用。
欢迎来到框架篇😎😎😎
Spring
什么是IOC?
维基百科介绍

我的理解
IOC?控制怎么实现反转了?
IOC-- Inversion Of Control即控制反转,就是把Bean创建流程的控制权(也就是创建对象的过程)交给了Spring来进行管理,降低代码间的耦合度。
实现
IOC的方式有两种:
依赖注入-DI--Dependency Injection和依赖查找-DL--Dependency Lookup
技术描述:
例如:
class 张三 {
}
class 李四 {
// 需要手动 new 出来
张三 zs = new 张三();
}
// 通过注解,把 Bean 注入 Spring 容器
@Component
class 张三 {
}
class 李四 {
// 因为张三的 Bean 已注入容器中,所以可以直接取出使用
@Autowire
private 张三 zs;
}
因此,控制反转就是:本来是代码中 new 出一个对象,代码拥有控制权,然后在 Spring 中,通过@Component注解,把类表示为Spring的一个组件,被标记的类就会被Spring自动扫描,然后作为Bean注册到Spring的IOC容器中。然后控制权就交给了Spring,随用随取。
什么是AOP?
维基百科介绍

我的理解
什么是
AOP?
简单来说,AOP就是为了更加优雅的编写业务、专注于业务开发、增加代码可读性,将一些具有某种功能的代码抽取出来,然后通过Spring AOP注解的形式注入使用。
怎么实现?
AOP的相关注解:
| 注解 | 含义 |
|---|---|
| @Aspect | 定义切面类 |
| @Pointcut | 定义切入点,表示在哪些连接点上切入执行增强操作 |
| @Before | 表示在目标方法执行之前执行增强操作 |
| @After | 表示在目标方法执行之后(无论是否发生异常)执行增强操作 |
| @AfterReturning | 在目标方法执行之后(正常返回时)执行增强操作 |
| @AfterThrowing | 在目标方法执行之后(发生异常时)执行增强操作 |
| @Around | 包围目标方法,可以在执行前后自定义增强操作 |
| @DeclareParents | 引入新的接口到目标对象 |
这些注解可以与其他Spring注解一起使用,例如
@Component、@Service、@Controller等,以实现对特定方法或类的增强操作。通过使用这些注解,您可以在不修改原始代码的情况下,将横切关注点(例如日志记录、事务管理等)模块化地应用到应用程序中的不同部分。
实例:
假设我们有一个
UserService接口和一个UserServiceImpl类,现在我们想要在createUser方法执行前后添加日志记录的功能。public interface UserService { void createUser(String username, String password); } public class UserServiceImpl implements UserService { public void createUser(String username, String password) { // 创建用户的实现逻辑 } }创建一个切面类,并在切面类的方法上使用
@Around注解来定义环绕通知:@Aspect @Component public class LoggingAspect { private static final Logger logger = LoggerFactory.getLogger(LoggingAspect.class); @Around("execution(* com.example.service.UserService.createUser(..))") public Object logMethodExecution(ProceedingJoinPoint joinPoint) throws Throwable { String methodName = joinPoint.getSignature().getName(); logger.info("Executing method: {}", methodName); // 执行目标方法 Object result = joinPoint.proceed(); logger.info("Method {} executed successfully", methodName); return result; } }
知识扩展
这行代码怎么理解?
execution(* com.example.service.*.*(..))
execution(* com.example.service.*.*(..)) 是一个切入点表达式(Pointcut Expression),它用于指定切入点的位置。
切入点表达式由以下几部分组成:
execution: 指定切入点类型为方法执行。*: 匹配任意返回类型的方法。com.example.service: 指定目标方法所在的包路径。*.*: 第一个*表示任意类名,第二个*表示任意方法名。(..): 匹配任意参数类型和数量的方法参数。
所以,execution(* com.example.service.*.*(..)) 表示匹配 com.example.service 包下任意类的任意方法,并且方法的参数可以是任意类型和数量。
实际业务中经常使用
AOP的示例:日志记录和事务管理的结合
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.AfterReturning;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
@Aspect
@Component
public class LoggingAndTransactionalAspect {
private static final Logger logger = LoggerFactory.getLogger(LoggingAndTransactionalAspect.class);
@Before("execution(* com.example.service.*.*(..))")
public void logBefore(JoinPoint joinPoint) {
String methodName = joinPoint.getSignature().getName();
String className = joinPoint.getTarget().getClass().getSimpleName();
logger.info("Executing method {} in class {}", methodName, className);
}
@AfterReturning(value = "execution(* com.example.service.*.*(..))", returning = "result")
@Transactional
public void logAfterReturning(JoinPoint joinPoint, Object result) {
String methodName = joinPoint.getSignature().getName();
String className = joinPoint.getTarget().getClass().getSimpleName();
logger.info("Method {} in class {} executed successfully. Result: {}", methodName, className, result);
}
}
增加了@Transactional注解。这意味着在目标方法执行后,会自动开启事务并提交事务。这样,我们就实现了日志记录和事务管理的结合。
@Component:通用的注解,用于标识一个类为 Spring 组件。被@Component注解标记的类将被自动扫描并注册为 Spring 的 bean。@Controller:用于标识一个类为 MVC 控制器的组件。通常用于处理用户请求和返回视图。@Service:用于标识一个类为业务逻辑层的组件。通常用于封装业务逻辑,并被其他组件调用。@Repository:用于标识一个类为数据访问层的组件。通常用于封装数据库操作,与数据库进行交互。@Autowired:用于自动装配依赖关系。通过@Autowired注解,Spring 将自动在应用程序上下文中查找匹配的 bean,并将其注入到标记了@Autowired的字段、构造函数或方法参数中。@Qualifier:用于指定具体的 bean,当存在多个匹配的候选 bean 时,可通过@Qualifier注解指定要注入的 bean。@Value:用于注入配置属性值。通过@Value注解,可以将配置文件中的值注入到标记了@Value的字段或方法参数中。@RequestMapping:用于映射请求路径到处理方法。通过@RequestMapping注解,可以定义处理特定请求的方法,并指定请求的 URL、HTTP 方法、请求参数等。
Spring 是什么?
Spring 是一个功能强大的企业级开发框架,提供了一系列的模板,用来支持不同的应用需求,如:依赖注入(DI)、面向切面编程(AOP)、事务管理、Web 应用程序开发等。然后 Spring Boot 框架的出现,主要起到了简化 Spring 应用程序的开发,有利于快速构建开发应用程序。
Spring Boot 提供了什么功能?
- 自动装配
通过依赖一个 spring-boot-starter-xxx 的依赖,然后通过配置文件来简化配置,简化业务逻辑的开发。
- 内嵌 Web 服务器
Spring Boot 内置了Tomcat和JettyWeb 服务器,所以无需另外下载Web服务器便可以运行程序。
那么是如何启动Web项目的呢?
如图:

我们可以看到,在main方法中有一个SpringApplication类的静态方法run()来启动Web项目,然后Spring Boot会扫描我们的全局依赖,然后结合配置文件中的配置来启动程序。
-
约定大于配置思想
简单来说就是配置与业务分离,而且并不需要开发者关心配置如何实现的,只需在配置文件中编写相关配置即可。例如:应用程序通过读取
application.yml或者application.properties文件获取配置,极大程度上,让开发者更加专注于应用程序的开发。
欢迎来到中间件篇😎😎😎
RabbitMQ
介绍一下RabbitMQ?
RabbitMQ就是一个实现了一个AMQP协议的开源消息代理软件,即高级消息队列协议(Advance Message Queen Protocol),RabbitMQ的服务器是由ErLang语言编写的,故拥有高性能、健壮、可伸缩性的优点。
了解RabbitMQ的架构吗?
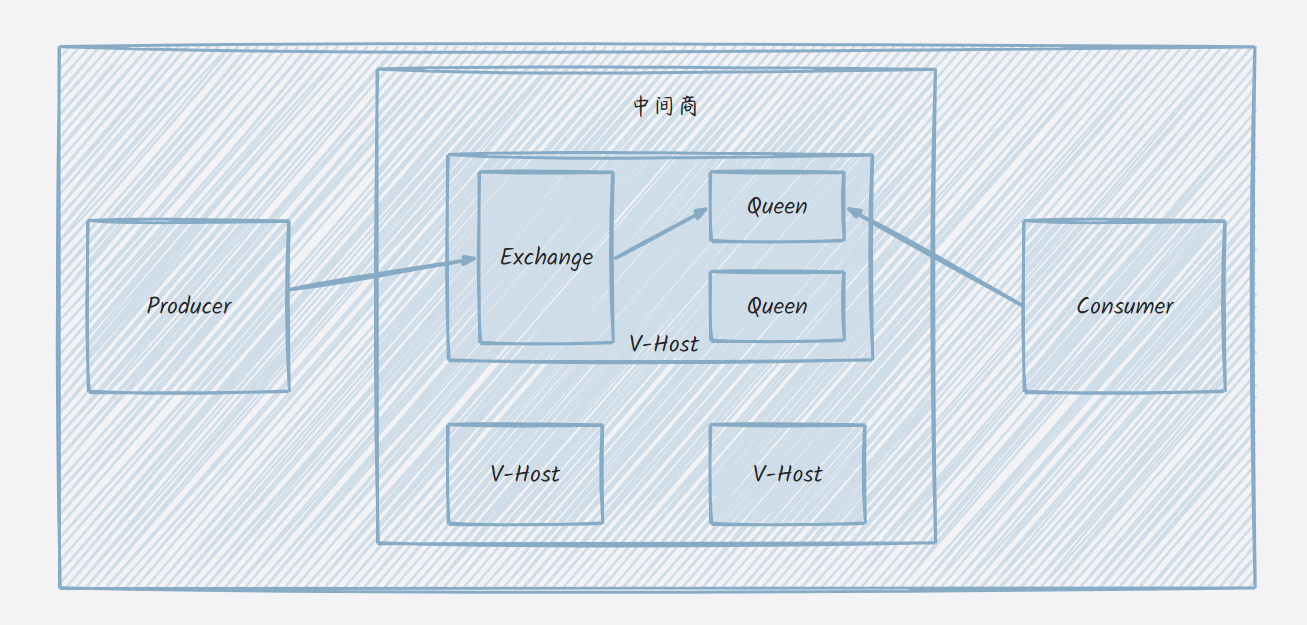
- Producer:生产者
- Consumer:消费者
- V-host:虚拟主机
- Exchange:交换机
- Queen:消息队列
在你的项目中为什么不用RocketMQ?
首先,RabbitMQ是支持多种语言的,并且可以设置任意时长的TTL存活时间,另外还有一个可视化管理页面,可以更加清晰的检查消息的生产与消费,其次,我更加熟悉RabbitMQ的使用,比如怎么做消息分发、如何实现延迟消息队列、配置死信队列等等(抛出话题,指引方向)
消息分发
消息分发方式?
怎么配置死信队列
架构图?
欢迎来到微服务篇😎😎😎
微服务
什么是微服务
维基百科
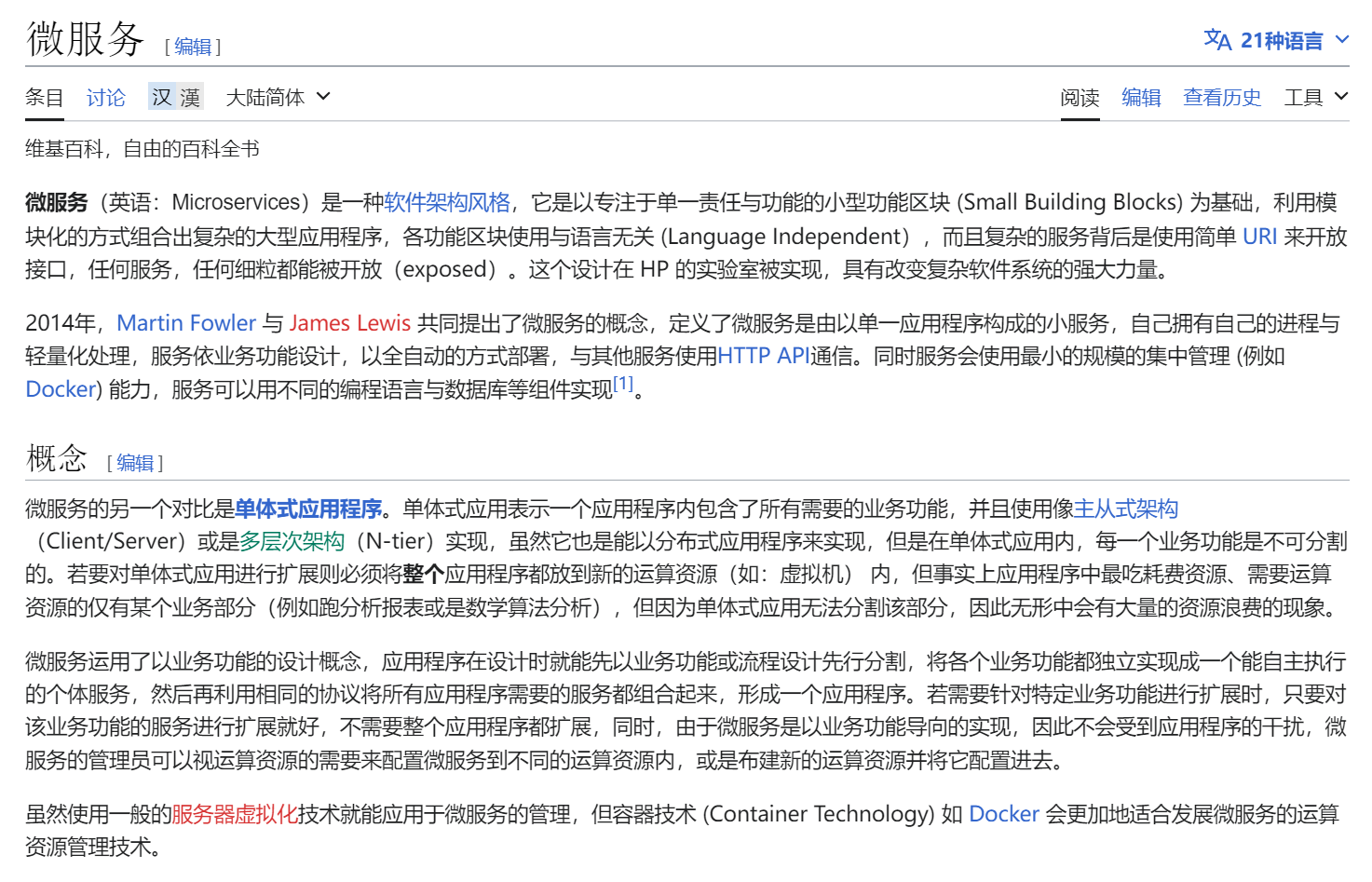
一个微服务框架的应用程序有下列特性:
- 每个服务都容易被取代。
- 服务是以能力来组织的,例如用户界面、前端、推荐系统、账单或是物流等。
- 由于功能被拆成多个服务,因此可以由不同的编程语言、数据库实现。
- 架构是对称而非分层(即生产者与消费者的关系)。
一个微服务框架:
- 适用于具持续交付(Continuous Delivery)的软件开发流程。
- 与服务导向架构(Service-Oriented Architecture)不同,后者是集成各种业务的应用程序,但微服务只属于一个应用程序。
杂谈:
- 为什么一些高并发平台都属于微服务架构?
比如说语雀 APP ,虽然不小心挂掉之后,经过长达多个小时的紧急抢修,服务得意重新上线。
- 从这次 P0 级事故,我们可以学到什么?

微服务实现技术
Spring CloudSpring Cloud AlibabaDubboRPC(GRPC、TRPC)
微服务的本质: 就是通过HTTP、或者其他网络通讯协议进行相互调用而实现的。
知识扩展
分布式与微服务的区别
简单来说: 分布式就是把一个大的项目拆分,部署到多台机器;微服务是把项目按照功能进行拆分。
面试问题:什么是分布式锁?什么是单机锁?
分布式锁?顾名思义,分布式锁就是要考虑到多台机器的场景
总结: 分布式项目对标单机项目; 微服务项目是与整个项目的业务逻辑进行对比的。
欢迎来到设计模式篇😎😎😎
设计模式
什么是设计模式?
顾名思义,无论是什么领域出现了模式相关的东西,那么这些模式一定是相对于
原生来说,更加高效、更加优雅、可维护更强。
在软件工程中,设计模式(design pattern)是对软件设计中普遍存在(反复出现)的各种问题,所提出的解决方案。这个术语是由埃里希·伽玛(Erich Gamma)等人在1990年代从建筑设计领域引入到计算机科学的。
设计模式并不直接用来完成代码的编写,而是描述在各种不同情况下,要怎么解决问题的一种方案。面向对象设计模式通常以类别或物件来描述其中的关系和相互作用,但不涉及用来完成应用程序的特定类别或物件。设计模式能使不稳定依赖于相对稳定、具体依赖于相对抽象,避免会引起麻烦的紧耦合,以增强软件设计面对并适应变化的能力。
并非所有的软件模式都是设计模式,设计模式特指软件“设计”层次上的问题。还有其他非设计模式的模式,如架构模式。同时,算法不能算是一种设计模式,因为算法主要是用来解决计算上的问题,而非设计上的问题。
随着软件开发社群对设计模式的兴趣日益增长,已经出版了一些相关的专著,定期召开相应的研讨会,而且沃德·坎宁安(Ward Cunningham)为此发明了WikiWiki用来交流设计模式的经验。
总结:
我认为设计模式就是前人针对于各种各样的总结下来的精华。是完全可以直接复用,并且能够提高开发效率的一种模式。
Java中都有哪些设计模式?
很多人都说一共有 23 种设计模式,但是我们根据设计模式的定义来看,我认为MVC也是一种设计模式,所以,在强调了只要是基于原生、前辈们经验总结下来的设计思想,都可以说是一种设计模式。
常见的设计模式有:
-
工厂模式
创建一个工厂,用于创建对象。 目的:将对象的创建与使用分离,可以避免在代码中重复写对象创建的代码。
-
模板方法模式
抽出公共方法,然后复用
-
装饰器模式
继承,然后添加新的功能就叫装饰器
-
享元模式
-
适配器模式
将一个类的接口换成客户端希望的立一个接口,可以是原不兼容的类被使用。
-
单例模式
确保类只有一个实例,并只提供一个全局访问点。
设计模式的七大原则
| 原则 | 描述 |
|---|---|
SRP | Single Responsibility Principle(单一职责)—— 一个类只干一件事 |
OCP | Open Close Principle(开放关闭原则)—— 开放功能,关闭修改 |
LSP | 里氏替换原则 —— 任何一个父类都可以使用子类来替换,并且不影响程序正常执行 |
DIP | 依赖倒置原则 —— 高层模块要依赖于抽象接口 |
ISP | 接口隔离原则 —— 也就相当于接口单一职责,接口应该小而精,不包含多余的方法 |
CARP | 合成聚合复用原则 —— 少用继承,优先使用合成聚合来构建复杂对象 |
LoD | 迪米特法则 —— 松耦合Java中有哪些设计模式 |
欢迎来到噩梦篇(bushi)😎😎😎
算法
1. 二分查找
要求:在有序数组A内,查找值target
- 如果找到返回索引
- 如果找不到返回 -1
算法描述:
前提:给定一个内含n个元素的有序数组A,满足A0<=A1<=A2<=.....<=An-1一个待查值target
1、设置 i = 0, j = n-1
2、如果 i > j,结束查找,没找到
3、设置 m = floor ((i+j)/2),m为中间索引,floor是向下取整(小于等于(i+j)/2的最小整数)
4、如果target < Am设置 j=m-1,跳到第二步
5、如果Am < target设置 i = m + 1,跳到第二步
6、如果Am = target,结束查找,找到了
代码实现:
a表示待查找的升序数组,target表示待查找的目标
找到返回索引,找不到返回-1
public static int binarySearchBasic(int[] a, int target) {
int i = 0, j = a.length - 1; //设置指针和初值
while(i <= j){ //i~j范围内有东西
int m = (i + j) >>> 1;
if(target < a[m]){ //目标在左边
j = m - 1;
}else if(a[m] < target){ //目标在右边
i = m + 1;
}else{ //找到了
return m;
}
}
return -1;
}
注意:
1、为什么是 i<=j 意味着区间内有未比较的元素,而不用 i<j 呢?
答:i==j 意味着i,j 他们指向的元素也会参与比较,i<j 只意味着 m 指向的元素参与比较
2、为什么要用(i+j)>>> 1,而不是(i+j)/2 呢?
说明:>>>1 无符号右移一位 可以看作是 除以2向下取整
答:因为如果数组元素个数非常多,i+j的结果超出了java最大正整数表示范围就会显示为负数,而数组的索引不能是负数,所以只能用无符号右移运算符,在java中,总是把一个二进制数的最高位视为符号位,如果最高位为1,那么这个二进制数表示的数为负数
public static int binarySearchAlternative(int[] a, int target) {
int i = 0, j = a.length; //设置指针和初值,改动处
while(i < j){ //i~j范围内有东西,改动处
int m = (i + j) >>> 1;
if(target < a[m]){ //目标在左边
j = m; //改动处
}else if(a[m] < target){ //目标在右边
i = m + 1;
}else{ //找到了
return m;
}
}
return -1;
}
说明:改动之后的 j (初始的j)只是作为一个边界值并没有指向查找目标,而改动之前的 j 是直接指向最后一个数组元素,对比查找的值是要把 j 算在内的
所以改动之前的 i 和 j 可以称作左闭右闭边界,改动之后的 i 和 j 称作左闭右开边界
//a可以是无序数组
public static int linearSearch(int[] a, int target){
for (int i = 0; i<a.length;i++){
if (a[i] == target){
return i;
}
}
return -1;
}
怎么比较两个算法的优劣呢?可以比较两个算法的时间复杂度和空间复杂度
在计算机科学中,时间复杂度是用来衡量:一个算法的执行,随着数据规模的增大而增长的时间成本
时间复杂度不依赖于环境因素

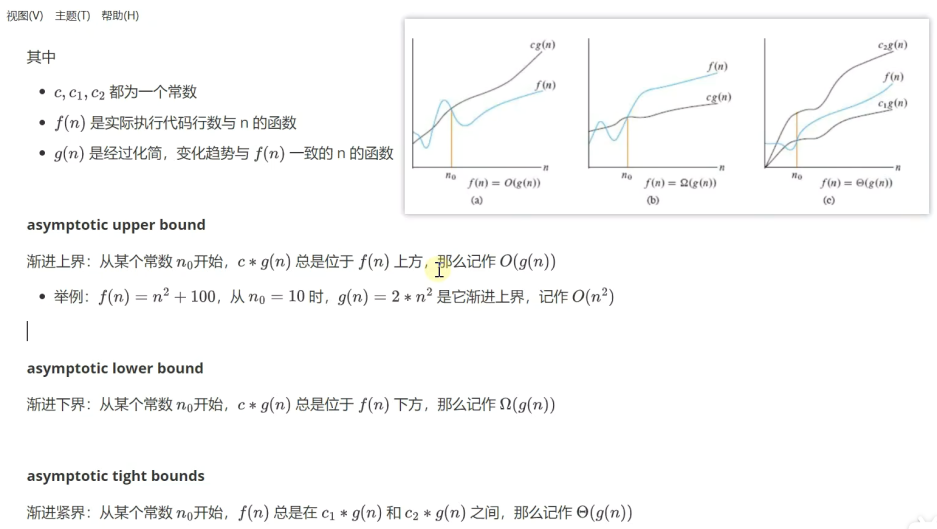
说明:渐进上界中的g(n)可以代表算法的最好情况 (大O表示法)
渐进下界的g(n)可以代表算法的最坏情况(欧米伽表示法)
渐进紧界的g(n)既能代表算法的最好也能代表算法的最坏情况(θ表示法)
常见的表示法一般用大O表示法
大O表示法的解析:
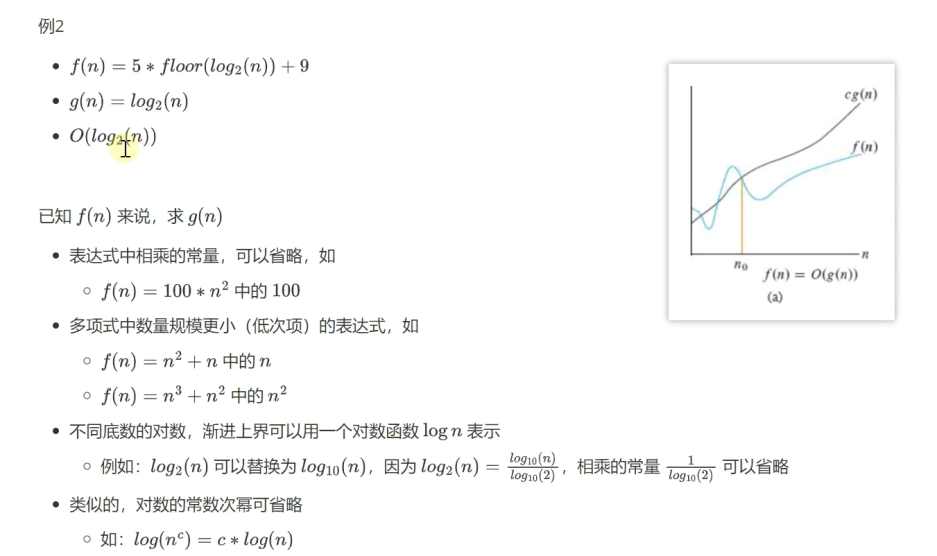
常见的大O表示法:
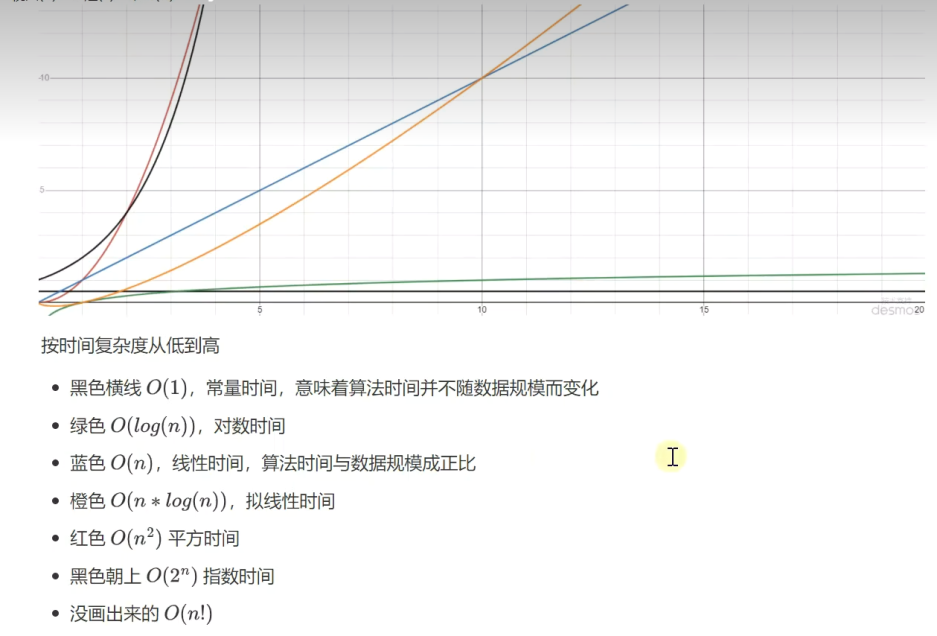
空间复杂度:
与时间复杂度类似,一般也用大O表示法来衡量:一个算法执行随数据规模增大,而增长的额外空间成本
二分查找的性能
分析:
时间复杂度
- 最坏情况:O(log(n))
- 最好情况:如果待查找元素恰好在数组中央,只需要循环一次O(1)
空间复杂度
- 需要常数个指针i,j,m,因此额外占用的空间是O(1)
public static int binarySearch3(int[] a, int target){
int i = 0, j = a.length;
while(1 < j - i){
int m = ( i + j ) >>> 1;
if(target < a[m]){
j = m;
}else{
i = m;
}
}
if(a[i] == target){
return i;
}else{
return -1;
}
}
优点:循环内的平均比较次数减少了
缺点:时间复杂度变为了θ(log(n))
在java中,可以通过Arrays找到二分查找的源代码,要使用的话就直接调用
@Test
public void test(){
int[] a = {2, 5, 8};
int target = 4;
int i = Arrays.binarySearch(a, target);
if(i < 0){
int insertIndex = Math.abs(i+1);//插入点索引,用Math.abs函数取绝对值
int[] b = new int[a.length + 1];
System.arraycopy(a, 0, b, 0, insertIndex);
b[insertIndex] = target;
System.arraycopy(a, insertIndex, b, insertIndex + 1, a.length - insertIndex);
}
}
查找最左侧重复元素
public static int binarySearchLeftmost1(int[] a, int target){
int i = 0, j = a.length - 1;
int candidate = -1;
while(i <= j){
int m = (i + j) >>> 1;
if(target < a[m]){
j = m - 1;
}else if(a[m] < target){
i = m + 1;
}else{
candidate = m; //记录后选位置
j = m - 1;
}
}
return candidate;
}
查找最右侧重复元素其实跟最左侧的代码基本一致:只需把else里的条件j = m - 1改为j = m + 1即可,这里就不写了
查找>=target的最靠左的索引位置
public static int binarySearchLeftmost2(int[] a, int target){
int i = 0, j = a.length - 1;
while (i <= j){
int m = (i + j) >>> 1;
if(target <= a[m]){
j = m - 1;
}else{
i = m + 1;
}
}
return i;
}
查找<=target的最靠右的索引位置
public static int binarySearchRightmost2(int[] a, int target){
int i = 0, j = a.length - 1;
while (i <= j){
int m = (i + j) >>> 1;
if(target < a[m]){
j = m - 1;
}else{
i = m + 1;
}
}
return i - 1;
}
查找最左、最右索引位置的应用:

排名:指查找的值target在这组数中排第几
前任:指比target小的更靠右的
后任:指比target大的更靠左的
最近邻居:指前任和后任中离target近的
求排名:排名=leftmost(target)+ 1
求前任:leftmost(target)- 1
求后任:rightmost(target)+ 1
求最近邻居就是把前任和后任都求出来在进行比较哪个更近就是哪个
范围查询:指找某个数组内<或者>或者=target值的范围
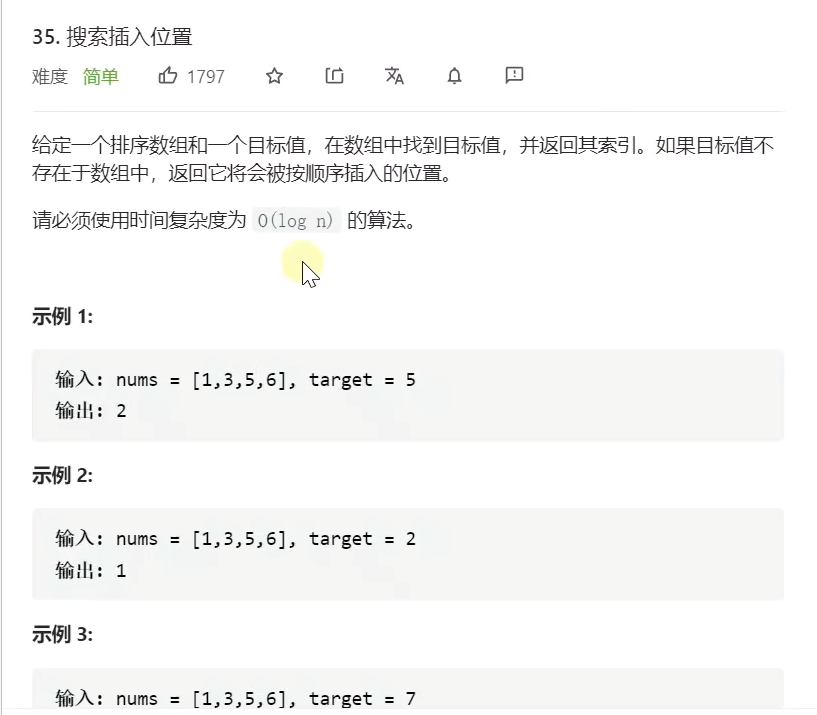
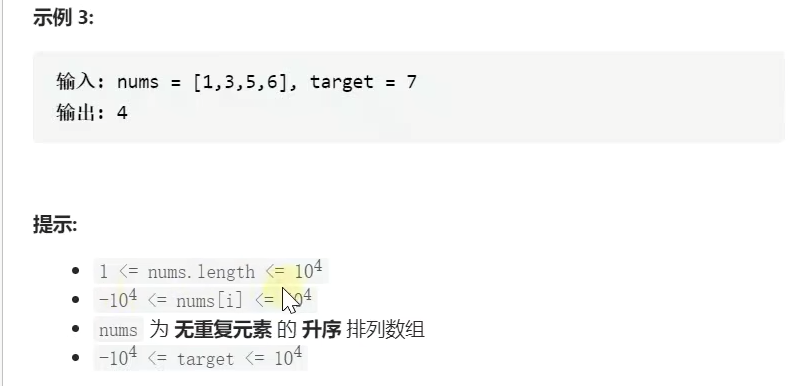
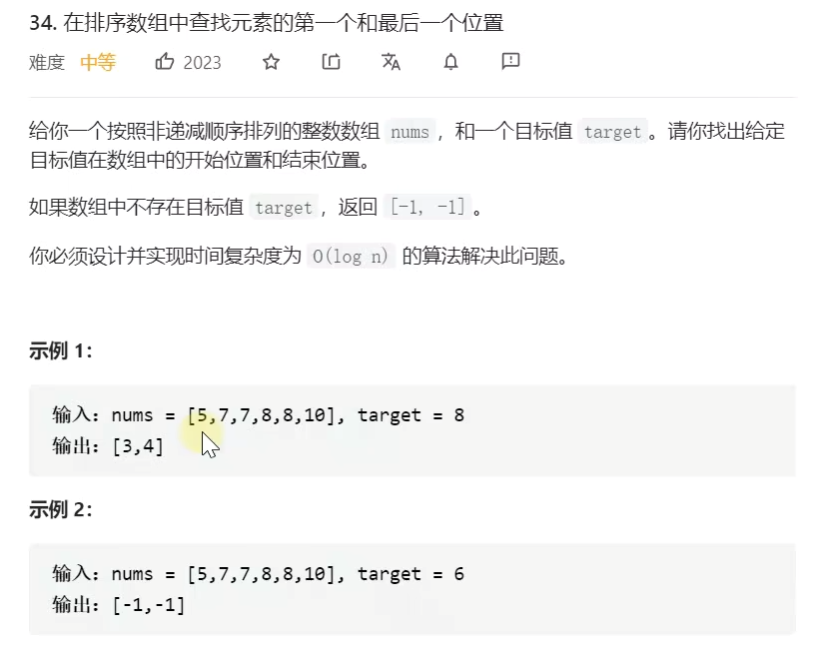
力扣题:
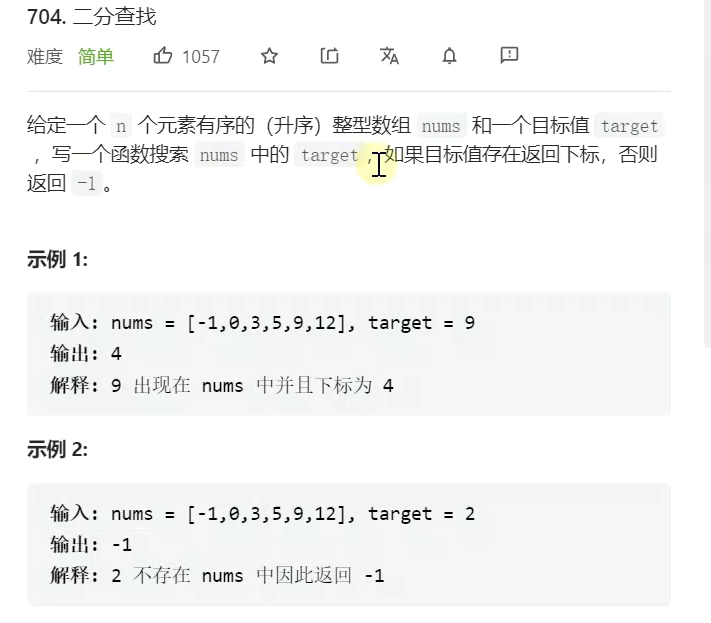
示例:
class Solution{
public int search(int[] nums, int target){
int i = 0, j = nums.length - 1;
while(i <= j){
int m = (i + j) >>> 1;
if(target < nums[m]){
j = m - 1;
}else if(nums[m]<target){
i = m + 1;
}else{
return m;
}
}
return -1;
}
}
class Solution{
public int search(int[] nums, int target){
int low = 0;
int high = nums.length - 1;
while(low <= high){
int m = (low + high) >>> 1;
long M = nums[m];
if(M < target){
low = m + 1;
}else if(target < M){
high = m - 1;
}else{
return m;
}
}
return low;
}
}

class Solution{
public int[] searchRange(int[] nums, int target){
int x = left(nums, target);
if(x == -1){
return new int[]{-1,-1};
}else{
return new int[]{x,right(a, target)};
}
}
public int left(int[] a,int target){
int i = 0,j = a.length - 1;
int candidate = -1;
while(i <= j){
int m = (i+j) >>> 1;
if(target < a[m]){
j = m - 1;
}else if(a[m] < target){
i = m + 1;
}else{
candidate = m;
j = m - 1;
}
}
return candidate;
}
public int right(int[] a,int target){
int i = 0,j = a.length - 1;
int candidate = -1;
while(i <= j){
int m = (i+j) >>> 1;
if(target < a[m]){
j = m - 1;
}else if(a[m] < target){
i = m + 1;
}else{
candidate = m;
i = m + 1;
}
}
return candidate;
}
}
2. 数组
定义:
在计算机科学中,数组是由一组元素(值或者变量)组成的数据结构,每个元素有至少一个索引或键来标识。
因为数组内的元素是连续储存的,所以数组内的元素的地址可以通过其索引计算出来。例如:int【】 array = {1,2,3,4,5} 这个数组内元素的索引为0,1,2,3,4 假设0这个索引的地址为b,那么1索引的地址就是b+4, 2索引的地址为b+8,以此类推。
知道了数组的数据起始地址BaseAddress,就可以由公式 BaseAddress+i * size 计算出索引 i 元素的地址。
- i 即索引,在java、C语言都是从0开始
- size 是每个元素占用字节,例如 int 型占4个字节,double 占8个字节
小测试
byte【】array = {1,2,3,4,5}
已知array的数据的起始地址是0x7138f94c8,那么元素3的地址是什么?
根据公式得:
BaseAddress + i * size = 0x7138f94c8 + 2 * 1 = 0x7138f94c10 = 0x7138f94ca
注意:10在16进制中为a
数组性能
空间占用
java中数组结构为
- 字节markword
- 4字节class指针(压缩 class指针的情况)
- 4字节数组大小(决定了数组最大容量是232)
- 数组元素+对齐字节(lava中所有对象大小都是8字节的整数倍12,不足的要用对齐字节补足)
例如
int【】array = {1, 2, 3, 4, 5} 的大小为40个字节,组成如下:
8 + 4 +4 + 5 * 4 + 4(alignment)
空间占用示意图:

随机访问
即根据索引查找元素,时间复杂度是O(1)
随机访问根数据规模没有关系
动态数组:
就是可以进行插入,删除元素,并且其大小可以根据自己的需要进行变化的数组称为动态数组,反之则为静态数组。
动态数组也支持扩容
public class DynamicArray{
private int size = 0; // size表示逻辑大小(控制数组内有效元素的个数)
private int capacity = 8; //容量
private int[] array = new int[capacity];//定义一个容量为8的空数组
//private int[] array = {}; //为了节省空间初始值可以设置成没有容量的空数组
//向最后位置【size】添加元素 element表示待添加的元素
public void addLast(int element){
array[size] = element;
size++;
//add1(size,element);//可以直接调用合并后的的代码实现
}
//向【0---size】位置添加元素 index表示索引位置 element表示待添加的元素
public void add(int index, int element){
//容量检查
checkAndGrow();
//添加逻辑
if(index >= 0 && index < size){
//向后挪动,空出待插入位置
System.arraycopy(array, index, array, index+1,
size - index);
array[index] = element;
size++;
}
}
//将以上两个方法合并的代码实现
public void add1(int index, int element){
if(index >= 0 && index < size){
System.arraycopy(array, index, array, index+1,
size - index);
}
array[index] = element;
size++;
}
//数组扩容
private void checkAndGrow(){
//容量检查
if(size == 0){
array = new int[capaity];//这个是将用到的空数组容量扩大到8,相当于上边的初始化容量为8的空数组
}else if(size == capacity){
//进行扩容,一般扩到原来的1.5,1.618,2倍大小
capacity += capacity >> 1;
int[] newArray = new int[capacity];
System.arraycopy(array, 0, newArray, 0, size);
array = newArray;
}
}
//删除元素
public int remove(int index){
int removed = array[index];
if(index < size - 1){
System,arraycopy(array, index + 1, array, index,
size - index - 1);
}
size--;
return removed;
}
//查询元素
public int get(int index){
return array[index];//返回该索引位置的元素
}
//遍历方法1
//为了不把遍历方法写死,而是把它作为参数传递进来以便于后续的操作
//例如:将数据传入到数据库中
//在java中传入一个consumer的函数式接口作为参数
public void forEach(Consumer<Integer> consumer){
for (int i = 0; i < size; i++){
//consumer能够实现这两个条件:提供array【i】,返回void
consumer.accept(array[i]);
}
}
}
public class DynamicArray implements Interable<Integer>{
//遍历方法2 迭代器遍历
@Override
public Iterator<Integer> iterator(){
return new Iterator<Integer>(){
int i = 0;
@Override
public boolean hasNext(){//有没有下一个元素
return i < size;
}
@Override
public Integer next(){//返回当前元素,并移动到下一个元素
return array[i++];
}
}
}
//遍历方法3 Stream流遍历
public IntStream stream(){
return IntStream.of(Arrays.copyOfRange(array, 0, size));
}
}
插入或删除性能
头部位置,时间复杂度是O(n)
中间位置,时间复杂度是O(n)
尾部位置,时间复杂度是O(1)(均摊来说)
二维数组
例:int【】【】 array = {
{11,12,13,14,15},
{21,22,23,24,25},
{31,32,33,34,35},
};
内存图如下:
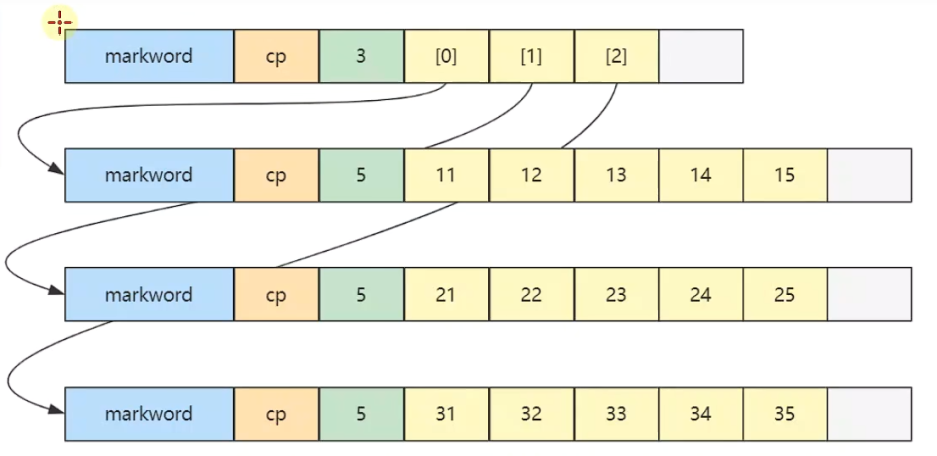
- 二维数组占32个字节,其中array【0】,array【1】,array【2】三个元素分别保存了指向三个一维数组的引用
- 三个一维数组各占40个字节
- 它们在内层布局上是连续的
怎么定位二维数组内的元素?
比如:要找上边那个数组中的25元素,它怎么表示呢?
答:array[i][j] = array[2][4] 其中 i = 外层数组索引位置,j = 内层数组索引位置
遍历二维数组中
先循环行,再循环列的代码实现效率高
局部性原理
这里只讨论空间局部性
- CPU读取内存(速度慢)数据后,会将其放入高速缓存(速度快)当中,如果后来的计算再用到此数据,在缓存中能读到的话,就不必读内存了
- 缓存的最小储存单位是缓存行,一般是64bytes,一次读的数据少了不划算,因此最少读取64bytes填满一个缓存行,所以读取某个数据时也会读取其临近的数据,这就是所谓的空间局部性
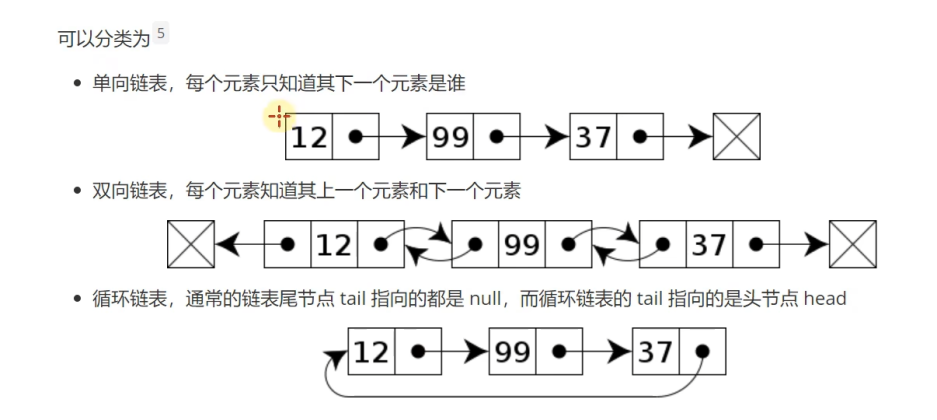
3. 链表
定义
在计算机科学中,链表是数据元素的线性集合,其每个元素都指向下一个元素,元素储存上并不连续。
分类:
public class SinglyLinkedList{//整体
private Node head = null;//头指针
//节点类
private static class Node{
int value;// 值
Node next; // 下一个节点指针
public Node(int value, Node next){
this.value = value;
this.next = next;
}
}
//向链表头部添加 添加值为 value
public void addFirst(int value){
//1.链表为空
head = new Node(value, null);
//2.链表非空
head = new Node(value,head);
}
//遍历链表
public void loop(){
Node p = head;
while(p != null){
System.out.println(p.value);
p = p.next;
}
}
//改动版,不写死
public void loop1(Consumer<Integer> consumer){
Node p = head;
while(p != null){
consumer.accept(p.value);
p = p.next;
}
}
//用for循环遍历
public void loop2(Consumer<Integer> consumer){
for(Node p = head; p != null; p = p.next){
consumer.accept(p.value);
}
}
//递归遍历
public void loop3(Consumer<Integer> before,
Consumer<Integer> after){
recursion(head, before, after);
}
private void recursion(Node curr,Consumer<Integer> before,
Consumer<Integer> after){//某个节点要进行的操作
if(curr == null){
return;
}
before.accept(curr.avlue);//输出值在递归之前和之后的顺序是不一样的
recursion(curr.next, before, after);
after.accept(curr.avlue);
}
//向链表尾部添加
private Node findLast(){
if(head == null){//空链表
return null;
}
Node p;
for(p = head; p.next != null; p = p.next){
}
return p;
}
public void addLast(int value){
Node last = findLast();
if(last == null){
addFirst(value);
return;
}
last.next = new Node(value, null);
}
//根据索引查找
//找到就返回该索引位置节点的值,找不到就抛出index非法异常
private Node findNode(int index){
int i = 0;
for(Node p = head; p != null; p = p.next, i++){
if(i == index){
return p;
}
}
return null; //没找到
}
public int get(int index){
Node node = findNode(index);
if(node == null){
throw new IllegalArgumentException(String.format(
"index [%d] 不合法%n", idnex));
}
return node.value;
}
//向索引位置插入 index表示索引,value表示待插入的值
public void insert(int index, int value){
if(index == 0){
addFirst(value);
return;
}
Node prev = findNode(index-1);//找到上一个节点
if(prev == null){
throw new IllegalArgumentException(String.format(
"index [%d] 不合法%n", idnex));
}
prev.next = new Node(value, prev.next);
}
//删除第一个节点
public void removeFirst(){
if(head == null){//如果只有一个头节点就抛一个异常
throw illegalIndex(0);//索引0没有可删除的节点
}
head = head.next;
}
//根据索引删除
public void remove(int index){
if(index == 0){
removeFirst();
return;
}
Node prev = findNode(index - 1);//上一个节点
if(prev == null){
throw illegalIndex(index);
}
Node removed = prev.next;//被删除的节点
if(removed == null){
throw illegalIndex(index);
}
prev.next = removed.next;
}
}
//迭代器遍历
public class SinglyLinkedList implements Interable<Integer>{
private Node head = null;
@Override
public Iterator<Integer> iterator(){
return new Iterator<Integer>(){
Node p = head;
@Override
public boolean hasNext(){//有没有下一个元素
return p != null;
}
@Override
public Integer next(){//返回当前元素,并移动到下一个元素
int v = p.value;
p = p.next;
return v;
}
}
}
}
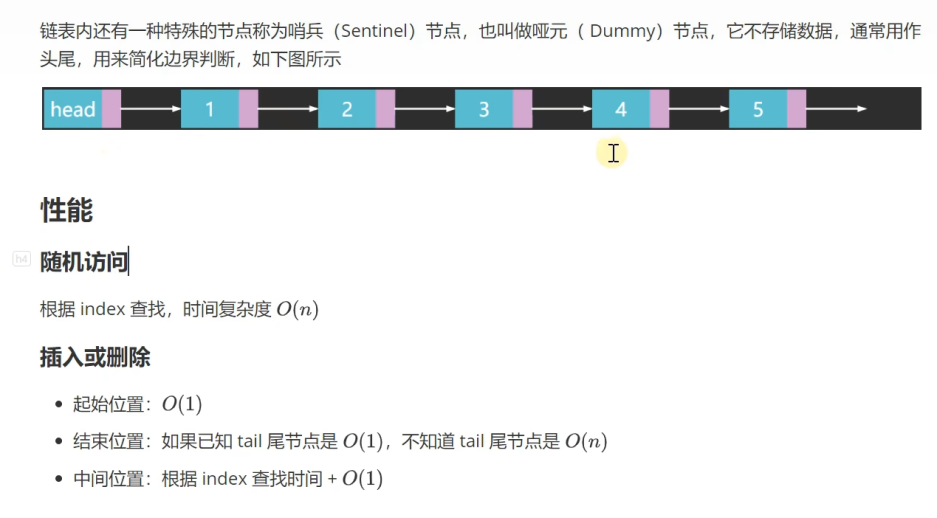
单向链表(带哨兵节点)
为什么要用哨兵节点?
是为了简化执行链表操作中的那些特殊情况的代码
什么特殊情况呢?比如:添加到尾部链表方法中的要考虑链表为空和非空的情况,按索引插入和删除的时候,找上一节点时需要考虑索引为0的情况,这些情况比较麻烦所以需要哨兵节点。
public class SinglyLinkedList{//整体
private Node head = new Node(666, null);//头指针指向哨兵节点
//节点类
private static class Node{
int value;// 值
Node next; // 下一个节点指针
public Node(int value, Node next){
this.value = value;
this.next = next;
}
}
//向链表头部添加 添加值为 value
public void addFirst(int value){
// //1.链表为空
// head = new Node(value, null);
// //2.链表非空
// head = new Node(value,head);
insert(0, value);
}
//遍历链表
//因为起点已经改为了哨兵,所以要从哨兵开始遍历
public void loop(){
Node p = head.next;//改动的地方
while(p != null){
System.out.println(p.value);
p = p.next;
}
}
//改动版,不写死
public void loop1(Consumer<Integer> consumer){
Node p = head.next;//改动了
while(p != null){
consumer.accept(p.value);
p = p.next;
}
}
//用for循环遍历
public void loop2(Consumer<Integer> consumer){
for(Node p = head.next; p != null; p = p.next){//改动了
consumer.accept(p.value);
}
}
//向链表尾部添加
//因为有了哨兵节点相当于在头部节点和0索引的节点之间加了一个节点
//0索引的节点的上一个节点是存在的(哨兵节点)
private Node findLast(){
// if(head == null){//空链表
// return null;
// }
Node p;
for(p = head; p.next != null; p = p.next){
}
return p;
}
public void addLast(int value){
Node last = findLast();
// if(last == null){
// addFirst(value);
// return;
// }
last.next = new Node(value, null);
}
//根据索引查找
//找到就返回该索引位置节点的值,找不到就抛出index非法异常
private Node findNode(int index){
int i = -1;//改动了
for(Node p = head; p != null; p = p.next, i++){
if(i == index){
return p;
}
}
return null; //没找到
}
public int get(int index){
Node node = findNode(index);
if(node == null){
throw new IllegalArgumentException(String.format(
"index [%d] 不合法%n", idnex));
}
return node.value;
}
//向索引位置插入 index表示索引,value表示待插入的值
public void insert(int index, int value){
// if(index == 0){
// addFirst(value);
// return;
// }
Node prev = findNode(index-1);//找到上一个节点
if(prev == null){
throw new IllegalArgumentException(String.format(
"index [%d] 不合法%n", idnex));
}
prev.next = new Node(value, prev.next);
}
//删除第一个节点
public void removeFirst(){
// if(head == null){//如果只有一个头节点就抛一个异常
// throw illegalIndex(0);//索引0没有可删除的节点
// }
// head = head.next;
remove(0);
}
//根据索引删除
public void remove(int index){
// if(index == 0){
// removeFirst();
// return;
// }
Node prev = findNode(index - 1);//上一个节点
if(prev == null){
throw illegalIndex(index);
}
Node removed = prev.next;//被删除的节点
if(removed == null){
throw illegalIndex(index);
}
prev.next = removed.next;
}
}
//迭代器遍历,遍历也需要改
public class SinglyLinkedList implements Interable<Integer>{
private Node head = new Node(666, null);
@Override
public Iterator<Integer> iterator(){
return new Iterator<Integer>(){
Node p = head.next;//改动的地方
@Override
public boolean hasNext(){//有没有下一个元素
return p != null;
}
@Override
public Integer next(){//返回当前元素,并移动到下一个元素
int v = p.value;
p = p.next;
return v;
}
};
}
}
双向链表(哨兵)
有两个指针组成的链表叫做双向链表
哨兵有两个:一个头部哨兵,一个尾部哨兵
public class DoubleLinkedListSentinel implements Iterable<Integer>{
static class Node{
Node prev;//上一个节点指针
int value;//值
Node next;//下一个节点指针
public Node(Node prev, int value, Node next){
this.prev = prev;
this.value = value;
this.next = next;
}
}
private Node head;//头哨兵
private Node tail;//尾哨兵
public DoubleLinkedListSentinel(){
head = new Node(null, 666, null);
tail = new Node(null, 888, null);
head.next = tail;
tail.prev = head;
}
//根据索引位置查找
private Node findNode(int index){
int i = -1;
for(Node p = head; p != tail; p = p.next, i++){
if(i == index){
return p;
}
}
return null;
}
//向链表头部添加节点
public void addFirst(int value){
insert(0, value);
}
//删除链表第一个节点
public void removeFirst(){
remove(0);
}
//向尾部添加
public void addLast(int value){
Node last = tail.prev;
Node added = new Node(last, value, tail);
last.next = added;
tail.next = added;
}
//删除链表尾部节点
public void reomeLast(){
Node removed = tail.prev;
if(removed == head){
throw illegalIndex(0);
}
Node prev = removed.prev;
prev.next = tail;
tail.prev = prev;
}
//根据索引位置插入
public void insert(int index, int value){
Node prev = findNode(index - 1);
if(prev == null){
throw illegalIndex(index);
}
Node next = prev.next;
Node inserted = new Node(prev, value, next);
prev.next = inserted;
next.prev = inserted;
}
//根据索引删除
public void remove(int index){
Node prev = findNode(index - 1);
if(prev == null){
throw illegalIndex(index);
}
Node removed = prev.next;
if(removed == tail){
throw illegalIndex(index);
}
Node next = removed.next;
prev.next = next;
next.prve = prev;
}
//异常处理
private IllegalArgumentException illegalIndex(int index){
return new IllegalArgumentException(
String.format("index [%d] 不合法%n", index));
}
//迭代器遍历
@Override
public Iterator<Integer> iterator(){
return new Iterator<Integer>(){
Node p = head.next;
@Override
public boolean hasNext(){
return p != tail;
}
@Override
public Integer next(){//返回当前元素,并移动到下一个元素
int value = p.value;
p = p.next;
return value;
}
};
}
}
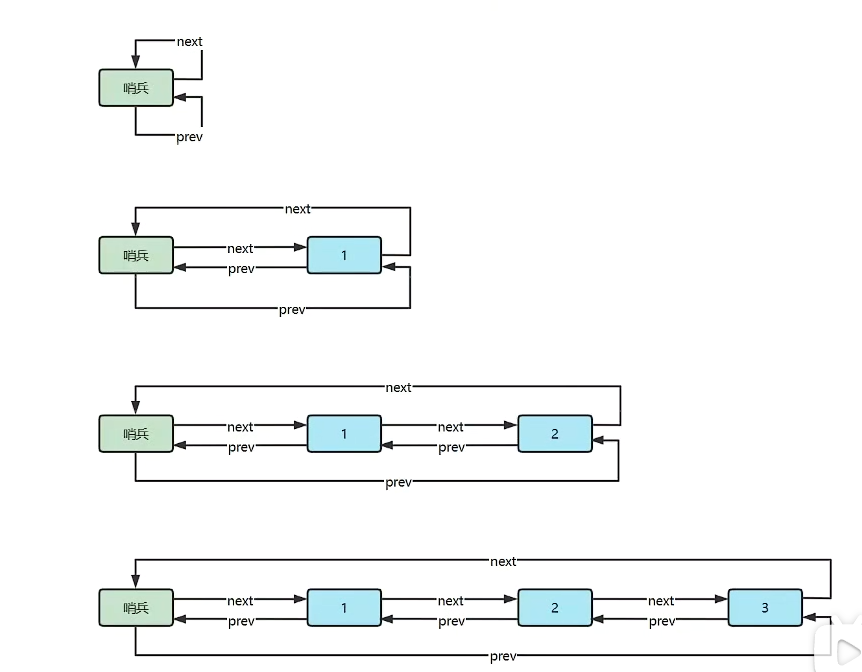
环形链表
双向环形链表带哨兵,这时的哨兵既作为头,也作为尾。
public class DoublyLinkedListSentinel implements Interable<Integer>{
//迭代器遍历
@Override
public Iterator<Integer> iterator(){
return new Iterator<Integer>(){
Node p = sentinel.next;
@Override
public boolean hasNext(){
return p != sentinel;
}
@Override
public Integer next(){//返回当前元素,并移动到下一个元素
int value = p.value;
p = p.next;
return value;
}
};
}
private static class Node{
Node prev;//上一个节点指针
int value;//值
Node next;//下一个节点指针
public Node(Node prev, int value, Node next){
this.prev = prev;
this.value = value;
this.next = next;
}
}
private Node sentinel = new Node(null, -1, null);
public DoublyLinkedListSentinel(){
sentinel.prev = sentinel;
sentinel.next = sentinel;
}
//添加到第一个节点
public void addFirst(int value){
Node a = sentinel;
Node b = sentinel.next;
Node added = new Node(a, value, b);
a.next = added;
b.prev = added;
}
//添加到最后一个
public void addLast(int value){
Node a = sentinel.prev;
Node b = sentinel;
Node added = new Node(a, value, b);
a.next = added;
b.prev = added;
}
//删除第一个节点
public void removeFirst(){
Node removed = sentinel.next;
if(removed == sentinel){
throw new IllegalArgumentException("非法");
}
Node a = sentinel;
Node b = removed.next;
a.next = b;
b.prev = a;
}
//删除最后一个节点
public void removedLast(){
Node removed = sentinel.prev;
if(removed == sentinel){
throw new IllegalArgumentException("非法");
}
Node a = removed.prev;
Node b = sentinel;
a.next = b;
b.prev = a;
}
//根据值删除,首先要找到这个值
public void removeByValue(int value){
Node removed = findByValue(value);
if(removed == null){
return;//没找到这个值就不用删除
}
Node a = removed.prev;
Node b = removed.next;
a.next = b;
b.prev = a;
}
private Node findByValue(int value){
Node p = sentinel.next;
while(P != sentinel){
if(p.value == value){
return p;
}
p = p.next;
}
return null;
}
}
4. 递归
定义:
计算机科学中,递归是一种解决计算问题的方法,其中解决方案取决于同一类问题的更小子集。
比如单链表递归遍历的例子:
void f(Node node){
if(node == null){
return;
}
println("before:" + node.value);
f(node.next);
println("after:" + node.value);
}
说明:
1、自己调用自己,如果说每一个函数对应着一种解决方案,自己调用自己意味着解决方案是一样的(有规律的)
2、每次调用,函数处理的数据会较上次缩减(子集),而且最后会缩减至无需继续递归
3、内层函数调用(子集处理)完成,外层函数才能算调用完成
//假设有这样一个链表:1-> 2-> 3->null
void f(Node node = 1){
println("before:" + node.value);//输出结果:1
void f(Node node = 2){
println("before:" + node.value);// 2
void f(Node node = 3){
println("before:" + node.value);// 3
void f(Node node = null){
if(node == null){
return;
}
}
println("after:" + node.value); // 3
}
println("after:" + node.value);// 2
}
println("after:" + node.value);// 1
}
用递归方法的解题思路:

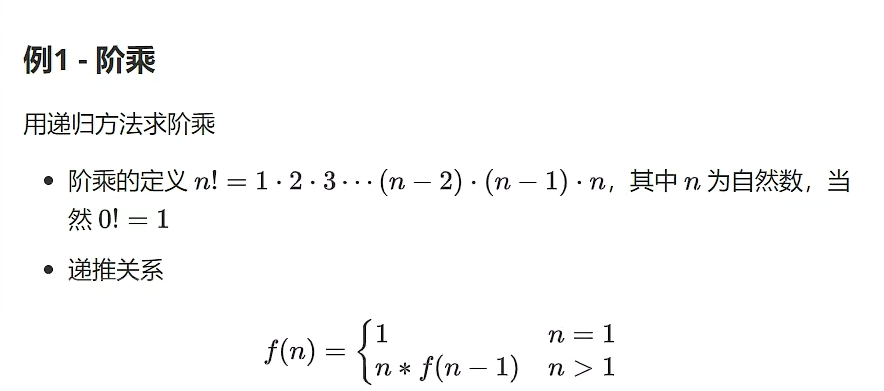
public class Factorial{
public static int f(int n){
if(n == 1){
return 1;
}
return n * f(n-1);
}
//测试5的阶乘
public static void main(String[] args){
int f = f(5);
System.out.println(f);
}
}

public class ReversePrintString{
public static void f(int n, String str){
if(n == str.length()){
return;
}
f(n + 1, str);
System.out.println(str.charAt(n));
}
//测试打印abcd
public static void main(String[] args){
f(0, "abcd");
}
}
用递归实现二分查找
public class E03BinarySearch{
public static int search(int[] a, int target){
return f(a, target, 0, a.length-1);
}
//递归(子问题)函数
//a表示数组,target表示待查找值,i表示起始索引(包含),j表示结束索引
//找到返回索引,找不到返回-1
private static int f(int[] a, int target, int i,int j){
if(i > j){
return -1;
}
int m = (i + j) >>> 1;
if(target < a[m]){
return f(a, target, i, m-1);
}else if(a[m] < target){
return f(a, target, m+1, j);
}else{
return m;
}
}
}
冒泡排序
所谓冒泡排序就是数组中相邻两个元素进行比较,大的放后面小的放前面或者小的放后面大的放前面,然后依次进行比较。
//将数组划分两部分【0---j】【j+1---a.length-1】
//左边【0---j】是未排序部分
//右边【j+1---a.length-1】是已排序部分
//未排序区间内,相邻两个元素比较,如果前一个大于后一个,则交换位置
public class E04BubbleSort{
//想使用递归方法实现冒泡排序可以直接调用这个函数
public static void sort(int[] a){
bubble(a, a.length - 1);
}
//j代表未排序区域右边界
private static void bubble(int[] a, int j){
if(j == 0){
return;
}
int x = 0;//中间加入一个x变量,优化了代码
for(int i = 0, i < j, i++){
if(a[i] > a[i+1]){
int t = a[i];
a[i] = a[i+1];
a[i+1] = t;
x = i;
}
}
bubble(a, x);
}
}
插入排序
所谓插入排序就是将一个记录插入到已经排好序的有序数组中,从而得到一个新的记录数加1的有序数组。
public class E05InsertionSort{
public static void sort(int[] a){
insertion(a, 1);
}
private static void insertion(int[] a, int low){
if(low == a.length){
return;
}
int t = a[low];
int i = low - 1;//已排序区域指针
while(i >= 0 && a[i] > t){//没有找到插入位置
a[i+1] = a[i];//空出插入位置
i--;
}
//找到插入位置
if(i + 1 ! = low){
a[i+1] = t;
}
insertion(a, low+1);
}
//另一种插入排序,这俩个排序方式时间复杂度一样,但是代码执行效率没有上面的高
private static void insertion2(int[] a, int low){
if(low == a.length){
return;
}
int i = low-1;
while(i >= 0 && a[i] > a[i+1]){
int t = a[i];
a[i] = a[i+1];
a[i+1] = t;
i--;
}
insertion(a, low + 1);
}
}
斐波那契数列
所谓斐波那契数列就是在一个数列中,从第二项开始,后一项是前两项之和
single recursion 单路递归 multi recursion 多路递归

public class E06Fibonacci{
public static int f(int n){
if(n == 0){
return 0;
}
if(n == 1){
return 1;
}
int x = f(n-1);
int y = f(n-2);
return x+y;
}
public static void main(String[] args){
int f = f(8);
System.out.println(f);
}
}

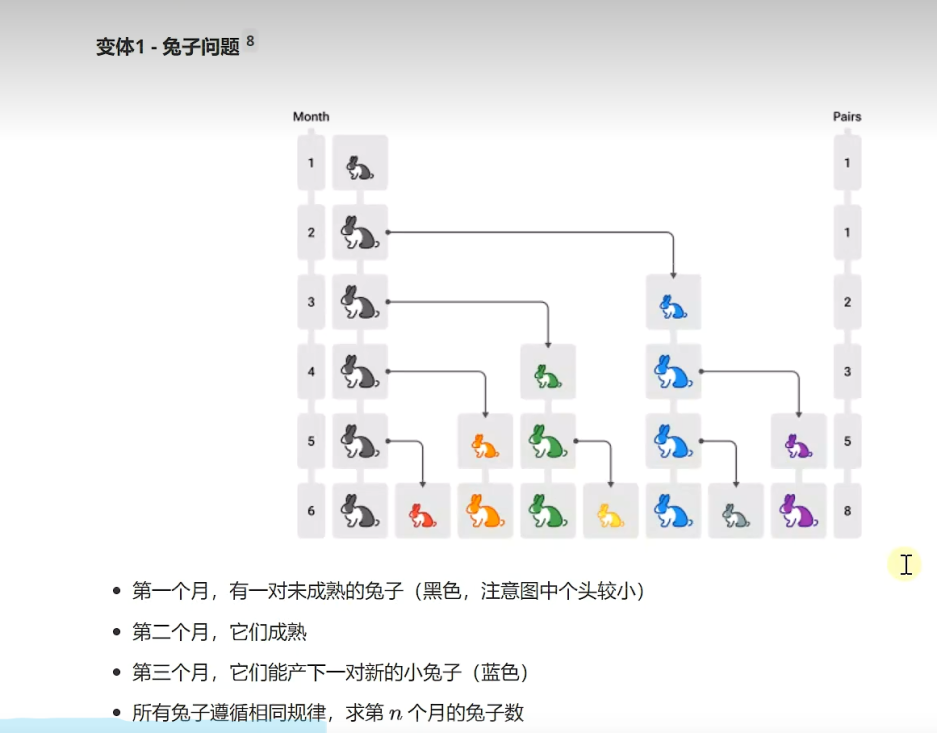
兔子问题规律:f(n) = f(n-1)+f(n-2) n是从第一项(F1)开始
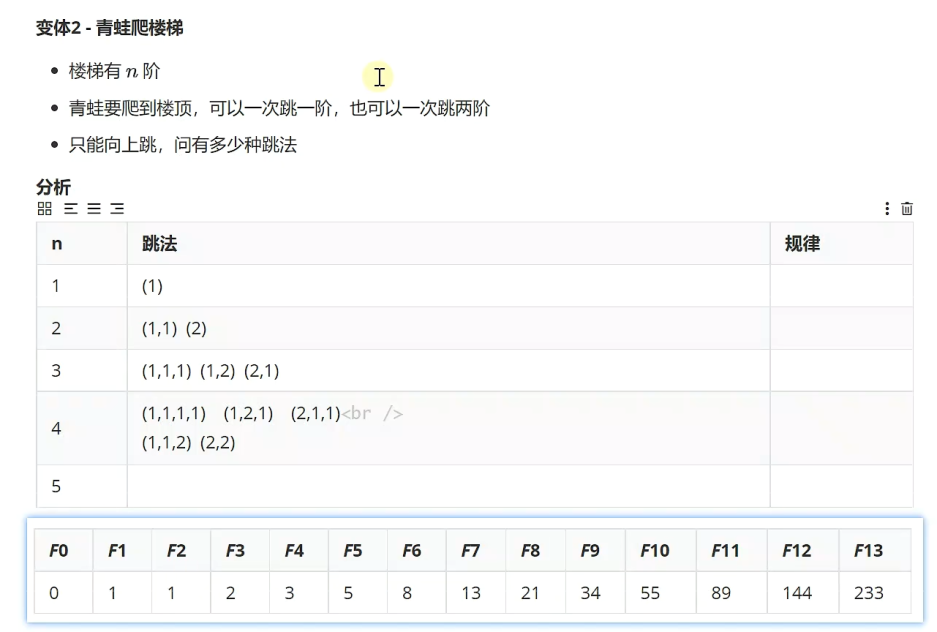
青蛙爬楼梯:n是从第二项(F2)开始,规律:f(n)=f(n-1)+f(n+1)
使用Memoization(记忆法或者叫备忘录)改进递归斐波那契代码
public class E01Finbonacci{
public static int fibonacci(int n){
int[] cache = new int [n+1];
Arrays.fill(cache, -1);//初始化数组为-1:[-1,-1,-1,-1,-1,-1]
cache[0] = 0;
cache[1] = 1;//[0,1,-1,-1,-1,-1]
return f(n);
}
public static int f(int n,int[] cache){
if(cache[n] != -1){
return cache[n];
}
int x = f(n-1, cache);
int y = f(n-2, cache);
cache[n] = x+y;//存入数组[0,1,?,-1,-1,-1]
return cache[n];
}
}
尾调用
如果函数的最后一步是调用一个函数,那么称之为尾调用,列如:
function a(){
return b();
}
//以下三段代码不能叫做尾调用
function a(){
const c = b();
return c;
}//最后一步不是调用函数
function a(){
return b() + 1;//虽然最后一步调用了函数,但又用到了外层函数的数值1
}
function a(){
return b() + x;//外层函数用到了变量x
}
尾递归是尾调用的一种特殊情况,就是调用的最后一步是这个函数本身,例如:
function a(){
return a();
}
一些语言的编译器能够对尾调用进行优化,例如:
//没优化之前
function a(){
return function b(){
return function c(){
return 1000;
}
}
}
//优化之后
a();
b();
c();
哪些语言能够对递归尾调用进行优化呢?
有C++,Scala等,scala与java有些相似,这里就用Scala,idea中可以用一个叫Scala的插件
object Main{
def main(args: Array[String]): Unit = {
println(sum(15000))
}
@tailrec//这个注解可以检查代码中是否用了尾递归
def sum(n: Long) : Long = {
if(n == 1){
return 1
}
return n + sum(n-1)
}
//优化后的代码,可以解决参数过大问题
def main(args: Array[String]): Unit = {
println(sum(15000, 0))
}
@tailrec//这个注解可以检查代码中是否用了尾递归 accumulator代表累加器
def sum(n: Long, accumulator : Long) : Long = {
if(n == 1){
return 1 + accumulator
}
return sum(n-1,n + accumulator)
}
}
要解决参数过大问题用尾递归优化限制太大,只能支持C++和Scala语言,所以我们可以从根本上解决,使用for循环
public static void main(String[] args){
long n = 10000000;
long sum = 0;
for(long i =n; i >= 1; i--){
sum += i;
}
System.out.println(sum);
}



第一章 基础数学思维与技巧
最大公约数
求最大公约数----欧几里得辗转相除法
public static int gcd(int a,int b){
while(b>0){
int temp = a%b;
a=b;
b=temp;
}
return a;
}
public static int gcd(int a,int b){
return b==0?a:gcd(b,a%b);
}
最小公倍数
求最大公倍数
public static int lcm(int a,int b){
return a * b / gcd(a,b);
}
进制转换
String s = Integer.toString(a,m);//10进制a数转m进制数,结果为字符串
int a = Integer.parseInt(s,m);//把字符串s当做m进制数,将结果转为10进制数
BigInteger biginteger = new BigInteger(s,m);//把m进制的字符串s转换成10进制数后封装成大数对象
位运算
与 & (全1为1,有0为0)
判断奇偶数
奇数-二进制最后一位一定为1 偶数-二进制最后一位一定为0
public static boolean check(int m){
return (m&1)==1;
}
判断m是否为2的x次方
若m为2的x次方:m的二进制只有最高位为1,其余全为0,(m-1)的二进制除最高位都为1.
public static boolean check(int m){
return m&(m-1)==0;
}
异或 ^ (相同为0,不同为1)
找到数组中只出现了一次的数
按位异或:相同为0,不同为1
x^x=0;
0^x=x;
a^b^c=a^c^b;
public static int num(int[] s){
int ans = 0;
for(int i=0;i<s.length;i++){
ans = ans ^ s[i];
}
return ans;
}
移位 >> 和<<
8>>1 == 4
4>>1 == 2
2<<1 == 4
4<<1 == 8
n >> m == n / (2 ^ m)
n << m == n * (2 ^ m)
素数
判断素数
素数:只有1和它本身是因数 。
首先,0和1不是素数,然后 i 从 2 开始判断 i 是不是 n 的因数,如果是因数,则直接返回 n 不是素数,否则,判断 i+1是不是 n 的因数,直到 i=√n 的时候,如果 i 仍然不是 n 的因数,那么 n 就是素数。
注:如果一个数 a 能够整除 i ,那么 i 和 a/i 一定满足:假设 i<=a/i , 那么 i<=√n , && a/i>= √n 。
public static boolean isprime(int n){
if(n==0 || n==1)
return false;
for(int i=2;i<=n/i;i++){
if(n%i==0)
return false;
}
return true;
}
求1~n中的所有素数----埃氏筛法
思路:如果一个数不是素数,那么这个数一定是 n 个素数的乘积(0和1除外),同理,素数的 k 倍数一定是合数(k>=2)。
public static void isprime(int n){
boolean[] isprime = new boolean[n+1];//false表示素数,true表示合数
for(int i=2;i*i<=n;i++)
if(!isprime[i]) //i是质数
for(int j=2;j*i<=n;j++)//将i的倍数全部标记为合数
isprime[i*j] = true;
for(int i=2;i<=n;i++)
if(!isprime[i])
System.out.println(i);
}
求1~n中的所有素数----欧拉筛法
思路:每个合数,只被他最小的质因子筛一次。
注:与埃氏筛法不同,埃氏筛法是将素数的倍数,标记为合数;欧拉筛法是将目前已经找到的每一个素数的 i 倍标记为合数,无论 i 是否是素数,同时,如果 i 本身就是素数的倍数,那么就去执行下一个 i 。
public static void isprime(int n){
boolean[] isprime = new boolean[n+1];
int[] prime = new int[n];//存储素数
int count = 0;//统计目前素数个数
for(int i=2;i<=n;i++) {
if(!isprime[i]) //i是质数
prime[count++] = i;//把当前素数存储到数组中count位置
for(int j=0;j<count && i*prime[j]<=n;j++){//将i的倍数全部标记为合数
isprime[i*prime[j]] = true;
if(i%prime[j]==0) break;//欧拉筛法精髓
}
}
for(int i=0;i<count;i++)
System.out.println(prime[i]);
}
例题:最小质因子之和
题目链接:最小质因子之和(Easy Version) - 蓝桥云课 (lanqiao.cn)

思路:因为题目输入为T组数据,如果单独计算每组数据,则会有部分区间的数据被重复计算,所以先通过埃氏筛法,求出每一个数的最小质因子,将结果存放在 ans 数组中,然后将 ans 数组表示为前缀和数组,此时 ans 数组中的结果就为2~n的质因子之和,此时,题目若输入 15 ,则直接输出 ans[15] 即可。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
public class 最小质因子之和 {
static boolean[] isprime = new boolean[3000001];//是否是素数
static long[] ans = new long[3000001];//存储最小质因子 i的最小质因子为ans[i],例:ans[4] = 2
static BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
static PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
public static void main(String[] args) throws IOException{
get(3000000);//题目数据范围,N最大值为3*10^6,将2~3*10^6中每一个数的最小质因子全部求出
for(int i=2;i<=3000000;i++) {
ans[i] = ans[i] + ans[i-1];//求前缀和,此时ans[i]中存放的数就是2~i中每一个数的最小质因子的和
}
int n = Integer.parseInt(in.readLine());
while(n-->0) {
out.println(ans[Integer.parseInt(in.readLine())]);
}
out.flush();
}
//找出每个数的质因子
static void get(int n) {
for(int i=2;i<=n;i++) {
if(isprime[i])//i不是质数直接跳过,不考虑,i不能作为筛除条件
continue;
ans[i] = i;//i为素数,素数的最小质因子就是其本身
for(int j=2;j<=n/i;j++) {//j为倍数,将素数i的j倍数标记为合数,并将此数的最小质因子标记为i
if(!isprime[j*i]) {//判断是否已经被标记过
isprime[j*i] = true;//将i*j标记为合数
ans[j*i] = i;//j*i的最小质因子是i
}
}
}
}
}
回文数
判断回文数
思路:将数字转换为字符串类型后,将此字符串倒转后,判断与原字符串是否相同
public static boolean check(int m){
return Integer.toString(m).equals(new StringBuffer(Integer.toString(m)).reverse().toString());
}
判断数组中元素是否相同
思路:若数组中元素全部相同,则数组中的最大值应当==最小值。
public static boolean check(int[] n){
Arrays.sort(n);
return n[0]==n[n.length-1];
}
思路:利用Set集合自动去重,将数组中所有元素全部添加到集合中后,如果集合中只有一个元素,则表示数组中所有元素全部相同。
public static boolean check(int[] n){
Set<Integer> set = new HashSet<>();
for(int i=0;i<n.length;i++) {
set.add(n[i]);
}
return set.size()==1;
}
日期+星期模拟
public static Main{
static int[] date = {0,31,28,31,30,31,30,31,31,30,31,30,31};//存储每月天数
static int y = 2001,m = 1;d = 1,week = 1;//初始年,月,日,星期(根据题意选择是否需要)
//week==0,表示周日,week==1,表示周一 ... week==6,表示周六
public static void main(String[] args){
int ans = 0;//计数
while(y!=9999 || m!=12|| d!=31){//设置日期判断范围
//判断闰年(满足其一即可):
//1.可以整除400
//2.可以整除4但不能整除100
if(y%400==0 || (y%4==0&& y%100!=0) date[2] = 29;
else date[2] = 28;
if(check()) ans++;//满足条件,计数器++;
d++;
week++;
week%=7;
if(d>date[m]){
d = 1;
m++;
}
if(m>12){
m = 1;
y++;
}
}
if(check()) ans++;//之前结束日期并未判断,判断结束日期
System.out.println(ans);
}
public static boolean check(){}//根据题目要求完成
}
约数
唯一分解定理

n的质因数个数----唯一分解定理
public static int num(long n){
int ans = 0;
for(int i=2;i<=n/i;i++){
while(n%i==0){
ans++;
n/=i;
}
}
if(n>1)
ans++;
return ans;
}
n的约数个数----唯一分解定理
public static int num(int n){
int cnt = 1;//乘法初始值为1
int bak = n;//备份n
for(int i=2;i*i<=n;i++){
int sum = 0;
while(bak%i==0){
sum++;
bak = bak / i;
}
cnt = cnt * (sum + 1);
}
if(bak>1) cnt*=2;
return cnt;
}
求n!的约数个数----唯一分解定理
public static long num(int n){
int[] prime = new int[n+1];//prime[i]表示素数i这个因子出现的次数
for(int i=2;i<=n;i++){
int bak = i;
for(int j=2;j*j<=bak;j++){
int sum = 0;
while(bak%j==0){
prime[j]++;
bak = bak / j;
}
}
if(bak>1) prime[bak]++;
}
long ans = 1;
for(int i=2;i<=n;i++){
if(prime[i]>1)
ans = ans * (prime[i]+1);
}
return ans;
}
例题:数数

思路:将这个区间中的每一个数都根据唯一分解定理进行拆分,统计有多少个数的拆分结果为12
import java.util.Scanner;
public class 数数 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int ans = 0;
for(int i=2333333;i<=23333333;i++)
if(num(i)==12)
ans++;
System.out.println(ans);
}
static int num(int n) {
int ans = 0;
for(int i=2;i<=n/i;i++) {
while(n%i==0) {
n/=i;
ans++;
}
}
if(n>1)
ans++;
return ans;
}
}
例题:求阶乘

思路:
1.根据唯一分解定理可知:每一个数都可以写为 n 个素数的乘积;
2.如果一个数的结尾有 0 的存在,那么这个数分解后一定有 2 和 5 (素数中,只有2 * 5才能使结尾产生 0 );
3.从 1 ~ N ,将每一个数都分解后,2 的数量一定比 5 多( 2 每隔两个数就会最少出现一个,5 每隔5个数,最少出现一个),那么,N!末尾 0 的数量,就是将 1 ~ N 中每个数分解后,5 的数量;
4.如果用一个循环从 5 开始,每次 +5 ,判断这些数可以拆分出几个 5 ,然后去找结尾有 k 个 0 的最小的 N 是多少,这个方法结果正确,但是时间复杂度会比较高,所以借助二分,去找到结尾有 k 个 0 的最小的 N 是多少;
5.用二分去查找,就必须做到:已知 N ,求出 1 ~ N 中可以拆分出多少个 5 ,以 125 为例,因为每五个数才拆分出 5 ,所以,如果 1~125 都只拆一个 5 ,则可以拆分出 125 / 5 共 25 个 5 ,拆分后的结果为 1 ~ 25 ,然后继续拆分 5 ,1 ~ 25 可以拆分出 25 / 5 个 5 ,拆分后结果为 1 ~ 5 ,1 ~ 5 可以拆分出 5 / 5 个 5 ,最后剩余 1 ,1 无法继续拆分出 5 ,所以 125 可以拆分出 25 + 5 + 1 = 31 个 5 ;
6.二分:如果mid拆分出的 5 的数量 >= k,那么可以 right = mid ,反之left = mid + 1,二分结果后,还需要判断它是否确实能拆分出 k 个 5 ,因为存在一个 N! 能恰好末尾有 k 个 0 ;
import java.util.Scanner;
public class 求阶乘 {
public static long find(long x) {//求x能拆分出多少个5
long res = 0;
while(x != 0) {
res = res + x / 5;
x/=5;
}
return res;
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
long k = sc.nextLong();
long l = 0,r = 100000;//防止溢出
while(l < r) {
long mid = (l + r) / 2;
if(k <= find(mid)) {
r = mid;
}else {
l = mid + 1;
}
}
if(find(r) != k) {//确保有解
System.out.println(-1);
}else {
System.out.println(r);
}
}
}
第二章 字符串基础
常用API
String m = "abcde";
char ch = m.charAt(String n);//获取字符串m的第(n+1)个字符
int length = m.length();//获取字符串m的长度
boolean flag = m.equals(String n);//判断字符串m和n是否相等,严格区分大小写
boolean flag = m.equalsIgnoreCase(String n);//判断字符串m和n是否相等,不区分大小写
int len = m.index(String s);//返回字符串s在m中第一次出现的位置
int compare = m.compareTo(String anotherString);//按字典序比较两个字符串,若compare>0,m大,若compare<0,m小
String s = m.concat(n);//将字符串n拼接到字符串m的结尾
boolean flag = m.contains(String n);//判断字符串m是否包含字符串n
boolean flag = m.endsWith(String s);//判断字符串m是否以字符串s结尾
String[] s = m.split(" ");//根据正则表达式拆分字符串m
String s = m.trim();//删除字符串m的前导空格和尾部空格
String s = m.subString(int i,int j);//截取字符串m中下标为i至下标为j-1的部分,即[i,j);
...
周期串
思路:从 1 开始枚举周期 T 的大小,然后判断每个周期内的对应字符是否相同,如果不同,则直接判断下一个 T 。
public static int cycle(String s){
char[] ch = s.toCharArray();
int T;
for(T=1;T<=ch.length;T++){
if(ch.length%T==0){//周期串的长度一定是周期T的倍数
boolean flag = true;
for(int start = T;start<ch.length;start++){
if(ch[start]!=ch[start%T]){
flag = false;
break;
}
}
if(flag){
break;
}
}
}
return T;
}
思路:pos 表示第二行的字符串向右移动的格数,如果移动后,第二行的字符串与第一行字符串对应位置的字符全部相同,则 pos 就是这个字符串的周期。

public static int cycle(String s){
String m = s+s;
int pos;
for(pos=1;pos<=s.length();pos++){
if(s.length()%pos!=0)
continue;
String x = m.substring(pos,pos+s.length());
if(x.equals(s))
break;
}
return pos;
}
思路:如果一个字符串 sub 是字符串 s 的周期,那么将字符串 s 中所有的 sub 全部替换为空字符串之后,字符串的长度如果为 0 ,就表示字符串 sub 是字符串 s 的周期。
public static int cycle(String s){
for(int i=1;i<=s.length();i++){
if(s.length()%i==0){
String sub = s.substring(0,i);
if(s.replace(sub,"").length()==0)
return i;
}
}
return 0;
}
例题:重复字符串
题目链接:重复字符串 - 蓝桥云课 (lanqiao.cn)

思路:已知重复次数为 K ,那么周期就是 S.length() / K ,然后只需要求出每一个周期的第 i 个字符,出现次数最多的字符是哪个,然后将其余字符全部改为它,那么就将 S 改为了重复 K 次的字符串,此时修改次数也是最少的。以abdcbbcaabca , 重复 3 次为例:
将此字符串拆分为三个部分后,每个周期写在一行,结果为:
abdc bbca abca
只需要求出每一个竖列出现次数最多的字符出现的次数,然后将其余字符全部改为它,那么这一列修改次数为(K - max),然后将每一列的结果加起来,即为答案。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
public class 重复字符串 {
static BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
static PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
public static void main(String[] args) throws IOException {
int n = Integer.parseInt(in.readLine());
String a = in.readLine();
if(a.length()%n!=0 || n>a.length()) {
System.out.println(-1);
return;
}
int t = a.length() / n;
int index = 0;
char[][] ch = new char[n][t];
for(int i=0;i<n;i++)
for(int j=0;j<t;j++)
ch[i][j] = a.charAt(index++);
int ans = 0;
for(int i=0;i<t;i++) {
int[] num = new int[26];
int max = 0;
for(int j=0;j<n;j++) {
num[ch[j][i]-'a']++;
if(max<num[ch[j][i]-'a']) {
max = num[ch[j][i]-'a'];
}
}
ans = ans + (n-max);
}
System.out.println(ans);
}
}
第三章 排序
冒泡排序
思路:每一次循环将最大值 / 最小值放于向后移动。
public static int[] sort(int[] a){
for(int i=0;i<a.length-1;i++){
for(int j=0;j<a.length-1-i;j++){
if(a[j]>a[j+1]){
int temp = a[j+1];
a[j+1] = a[j];
a[j] = temp;
}
}
}
return a;
}
插入排序
思路:第 i 趟,把第 i 个元素放到前 i - 1 个有序的序列中 。
public static int[] InsertSort(int[] a){
for(int i=1;i<a.length;i++){
int temp = a[i];//处理第i个元素
int j = i-1;
for(;j>=0 && a[j]>temp;j--){
a[j+1] = a[j];//大的元素往后移
}
a[j+1] = temp;
}
return a;
}
选择排序
思路:第 i 趟把从 i ~ 结尾最小的元素找到,放到 i 位置。
public static int[] SelectedSort(int[] a){
for(int i=0;i<a.length;i++){
int min = i;//存放i+1到最后最小的元素所在的下标
for(int j=i+1;j<a.length;j++){
if(a[j]<a[min])
min = j;
}
int temp = a[i];
a[i] = a[min];
a[min] = temp;
}
return a;
}
希尔排序
思路:将排序的区间分成若干个有跨度的子区间,对每一个子区间,进行插入排序,跨度不断 / 2 ,最终当跨度为 1 的时候,进行一个插入排序。
public static int[] shell(int[] a){
for(int gap = a.length/2;gap>0;gap/=2){
//对每一分组进行直接插入排序
for(int i=gap;i<a.length;i++){
int j = i;
while(j-gap>=0 && a[j-gap]>a[j]){//大的往后移动
int temp = a[j];
a[j] = a[j-gap];
a[j-gap] = temp;
j = j-gap;//下一次继续从分组的前一个位置开始
}
}
}
return a;
}
计数排序
思路:找出数组中的最大值和最小值,每个数都是在 min 和 max 之间,用一个长度为(max - min + 1)的数组 c 来存储每一个数出现的次数,然后将数组 c 转换为前缀和数组,则 c[ i ],就表示不大于(i+min)的元素的个数,按照 c 数组还原排序结果。
public static void countSort(int[] a){
int[] b = new int[a.length];
int max = a[0];min = a[0];
for(int i=0;i<a.length;i++){
if(a[i]>max) max = a[i];
if(a[i]<min) min = a[i];
}
int dis = max - min + ;
int[] c = new int[dis];
for(int i=0;i<a.length;i++)
c[a[i]-min]++;
for(int i=1;i<c.length;i++)
c[i] = c[i] + c[i-1];
for(int i=a.length-1;i>=0;i--){
b[c[a[i]-min]-1] = a[i];
c[a[i]-min]--;
}
System.out.println(Arrays.toString(b));
}
第四章 数据结构基础
链表
为什么要用链表
数组作为一个顺序储存方式的数据结构,可是有大作为的,它的灵活使用为我们的程序设计带来了大量的便利;但是,数组最大的缺点就是我们的插入和删除时需要移动大量的元素,所以呢,大量的消耗时间,以及冗余度难以接收。
链表可以灵活地去解决这个问题,插入删除操作只需要修改指向的对象就可以了,不需要进行大量的数据移动操作。
单链表
初始化
static class Node{//定义结点类
int value;//本身的值
Node next;//指向下一个结点
public Node(int value, Node next) {
this.value = value;
this.next = next;
}
}
Node head = new Node(-1,null);//头结点
Node end = new Node(-1, null);//尾结点
Node per = head;
for(int i=1;i<=10;i++) {
per.next = new Node(i, null);
per = per.next;
}
per.next = end;
插入
插入前:
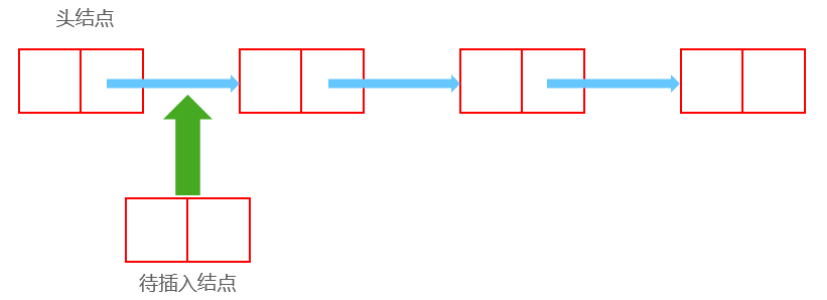
插入后:
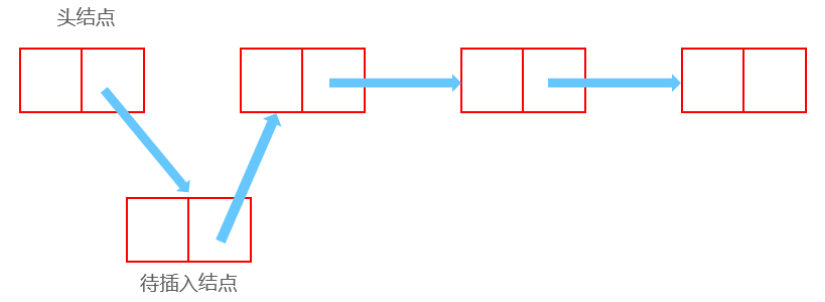
Node now;//待插入结点
now.next = head.next;//此节点的next为插入位置上一个结点的下一个结点
head.next = now;//此节点位置的上一个结点的下一个结点为now
删除
删除前:
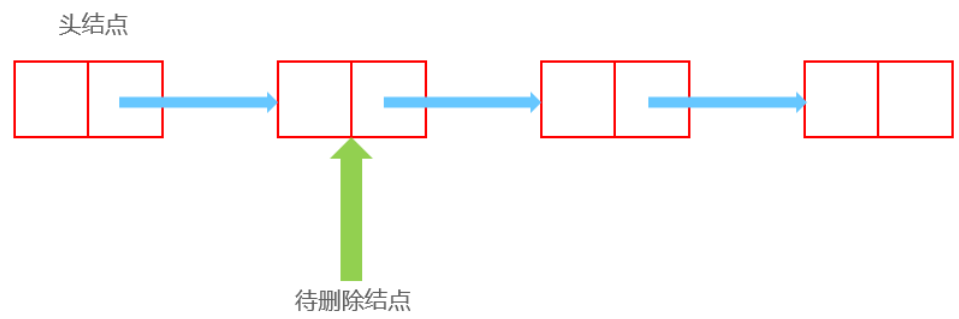
删除后:
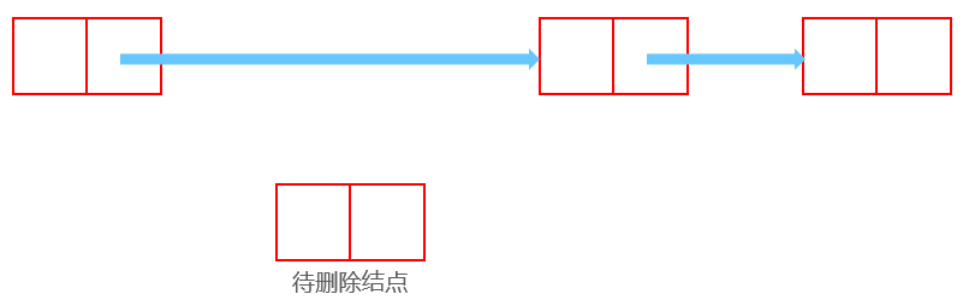
Node now;//待删除结点
head.next = now.next;
双链表
初始化
static class N{
N last;
int value;
N next;
public N(N last, int value, N next) {
this.last = last;
this.value = value;
this.next = next;
}
}
Node first = new Node(null,-1,null);//头结点
Node end = new Node(null,-1, null);//尾节点
Node per = first;
for(int i=1;i<=10;i++) {
per.next = new N(per,i, null);
per = per.next;
}
end.last = per;
per.next = end;
插入
插入前:
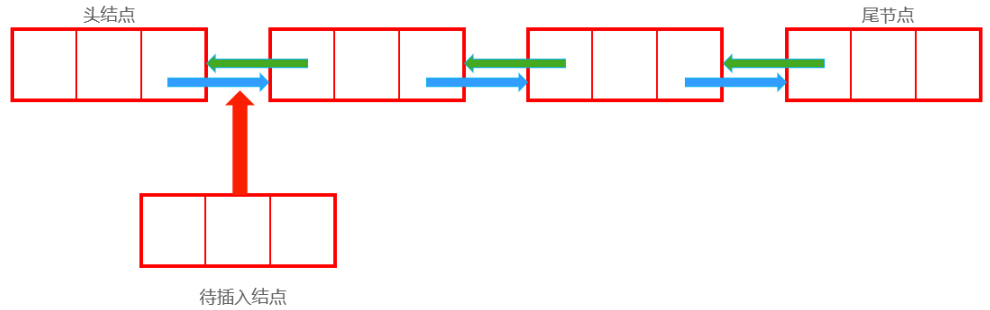
插入后:
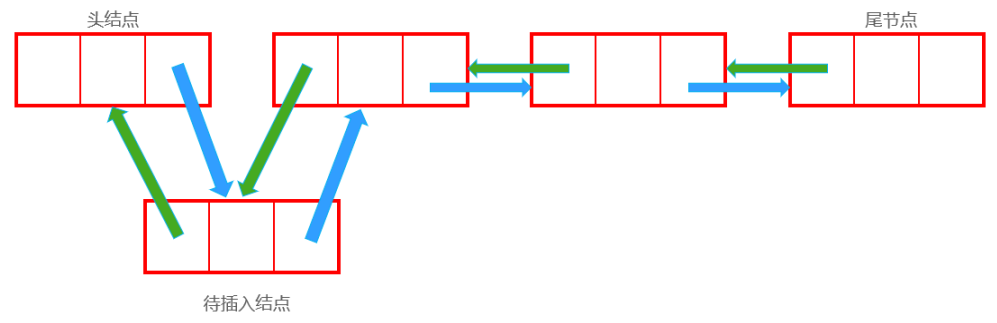
Node now;//待插入结点
now.next = first.next;
first.next.last = now;
first.next = now;
now.last = first;
删除
删除前:
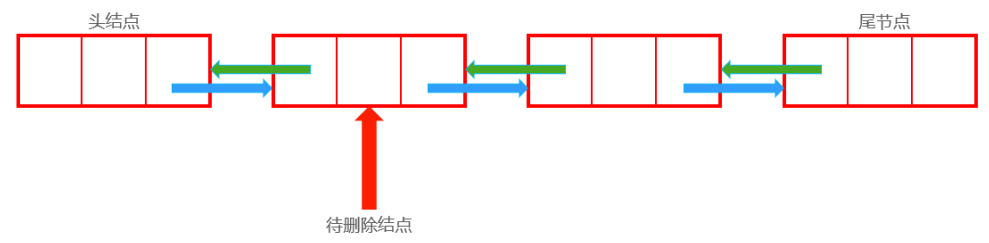
删除后:
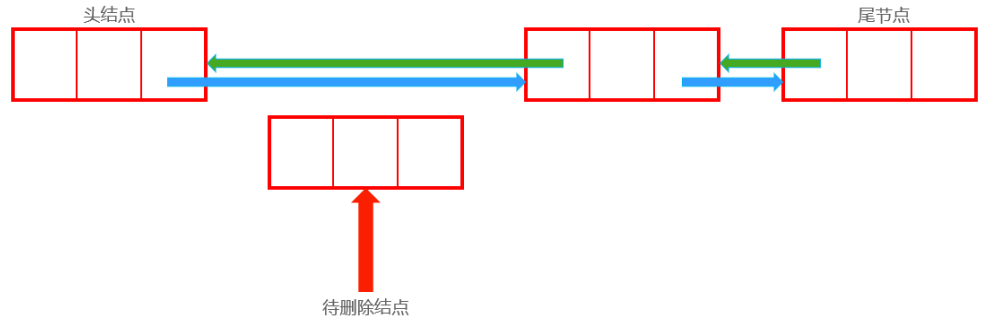
Node now;//待删除结点
now.last.next = now.next;
now.next.last = now.last;
例题:左移右移(双链表解法)

思路:
1.创建双链表并完成初始化,初始元素为 1 ~ n;
2.无论 x 左移或右移,都要先将 x 从原位置删除,为了便于获取 x 对应的 Node 结点,用 Map 存储 x 和 value 为 x 的结点;
3.如果 x 为左移,就将 x 对应的 Node 结点插入到头结点后;
4.如果 x 为右移,就将 x 对应的 Node 结点插入到尾节点前;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.util.HashMap;
import java.util.Map;
public class 左移右移_双链表 {
static class Node{
Node up;
int value;
Node down;
public Node(Node up, int value, Node down) {
this.up = up;
this.value = value;
this.down = down;
}
}
public static void main(String[] args) throws IOException{
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
String[] s = in.readLine().split(" ");
int n = Integer.parseInt(s[0]);
int m = Integer.parseInt(s[1]);
Map<Integer, Node> map = new HashMap<>();
Node first = new Node(null, -1, null);
Node last = new Node(null, -1, null);
Node no = first;
for(int i=1;i<=n;i++) {
no.down = new Node(no, i, null);
no = no.down;
map.put(i, no);
}
last.up = no;
no.down = last;
for(int i=0;i<m;i++) {
s = in.readLine().split(" ");
char ch = s[0].charAt(0);
int x = Integer.parseInt(s[1]);
Node node = map.get(x);
node.up.down = node.down;
node.down.up = node.up;
if(ch=='L') {
node.down = first.down;
first.down.up = node;
first.down = node;
node.up = first;
}else {
node.up = last.up;
last.up.down = node;
node.down = last;
last.up = node;
}
}
no = first.down;
while(no!=last) {
System.out.print(no.value+" ");
no = no.down;
}
}
}
栈
栈
栈(Stack):是只允许在一端进行插入或删除的线性表。首先栈是一种线性表,但限定这种线性表只能在某一端进行插入和删除操作。
栈顶(Top):线性表允许进行插入删除的那一端。
栈底(Bottom):固定的,不允许进行插入和删除的另一端。
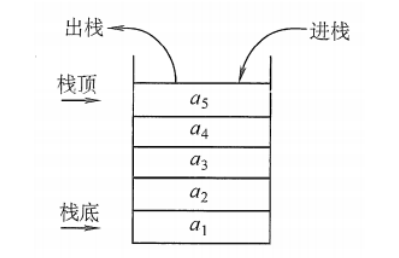
常用方法
Stack<Integer> stack = new Stack();
boolean is = stack.isEmpty();//判断此栈是否为空
int n = stack.peek();//获取栈顶的元素,但不删除
int m = stacl.pop();//获取并删除栈顶的元素
stack.push(10);//将10压入栈中
stack.clear();//清空栈
判断括号序列是否合法
public static boolean check(String s){
Stack<Character> stack = new Stack();
char[] ch = s.toCharArray();
for(int i=0;i<ch.length;i++){
if(ch[i]=='(')
stack.push(ch[i]);
else if(stack.isEmpty())
return false;
else
stack.pop();
}
return stack.isEmpty();
}
队列
队列
队列(queue)是一种先进先出的、操作受限的线性表。
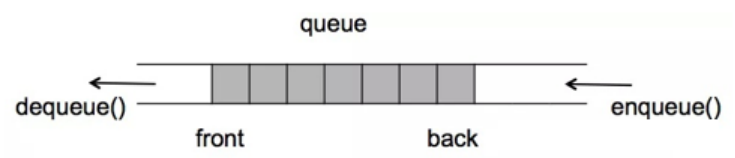
队列这种数据结构非常容易理解,就像我们平时去超市买东西,在收银台结账的时候需要排队,先去排队的就先结账出去,排在后面的就后结账,有其他人再要过来结账,必须排在队尾不能在队中间插队。
常用方法
Queue<Integer> queue = new LinkedList<>();
queue.peek();//获取队头元素,但不删除
queue.poll();//获取并删除队头元素
queue.clear();//清空队列
queue.push(11);//将11存放到队列中
例题:左移右移(栈 + 队列解法)

思路:
1.如果一个数先移动到最左边,再移动到最右边,那么最后输出的时候这个数一定是在最右边,也就是一个数最终出现在哪里,以他最后一次出现为准;
2.为了避免一个数重复判断,而且要以他最后一次出现时的 L 和 R 操作为最终操作,所以可以先将全部输入分别存放到 char 类型数组和 int 类型数组中,然后逆序判断,并且用一个数组来表示这个 x 有没有出现过;
3.因为要对输入做逆序操作,所以,逆序时最后出现的 L 对应的 x 在输出的最前面,然后之后出现的 L 对应的 x 依次输出,即先入先出,可以用队列来存储进行 L 操作的 x ;
4.逆序时最后出现的 R 对应的 x 在输出的最后面,然后之后出现的 R 对应的 x 依次在前,即后入先出,可以用栈来存储进行 R 操作的 x ;
5.输出时,先输出队列中的元素,然后将 1 ~ n 中没有出现过的值按序输出,最后输出栈中的元素;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;
public class 左移右移_栈_队列 {
public static void main(String[] args) throws IOException{
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
String[] s = in.readLine().split(" ");
int n = Integer.parseInt(s[0]);
int m = Integer.parseInt(s[1]);
int[] a = new int[n+1];
char[] c = new char[m];
int[] x = new int[m];
for(int i=0;i<m;i++) {
s = in.readLine().split(" ");
c[i] = s[0].charAt(0);
x[i] = Integer.parseInt(s[1]);
}
Stack<Integer> r = new Stack<>();
Queue<Integer> l = new LinkedList<>();
for(int i=m-1;i>=0;i--) {
if(a[x[i]]==0) {//判断x[i]是否出现过
a[x[i]] = 1;//若x[i]没有出现过
if(c[i]=='L')
l.add(x[i]);
else
r.push(x[i]);
}
}
while(l.size()!=0) //输出队列中元素
System.out.print(l.poll()+" ");
for(int i=1;i<=n;i++)
if(a[i]==0) //a[i]为0,表示i没有出现过
System.out.print(i+" ");
while(r.size()!=0) //输出栈中元素
System.out.print(r.pop()+" ");
}
}
第五章 分治算法
归并排序
思路:先把数组从中间分成前后两部分,然后分别对前后两部分进行排序,再将排好序的两部分数据合并在一起
public static void mergeSort(int[] a,int left,int right){//待排序数组,要排序的范围[left,right]
int mid = (left+right)>>1;
if(left<right){
mergeSort(a,left,mid);
mergeSort(a,mid+1,right);
merge(a,left,mid,right);
}
}
public static void merge(int[] a,int left,int mid,int right){
int[] temp = new int[right-left+1];//临时数组,用来归并
int i=left,j=mid+1,k=0;//左半段用i指向,右半段用j指向,temp数组用k指向
while(i<=mid && j<=right){
if(a[i]<a[j])
temp[k++] = a[i++];
else
temp[k++] = a[j++];
}
while(i<=mid) temp[k++] = a[i++];
while(j<=right) temp[k++] = a[j++];
for(int x=0;x<temp.length;x++){
a[left+x] = temp[x];
}
}
快速排序
思路:
(1)首先设定一个分界值,通过该分界值将数组分成左右两部分。
(2)将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于分界值,而右边部分中各元素都大于或等于分界值。
(3)然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
(4)重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。
public static void quickSort(int[] a,int left,int right){
if(left>right) return;//区间擦肩而过,无效,不需要进行递归
int i=left,j=right,temp = a[left];//a[left]作为基准点
while(i!=j){
while(a[j]>=a[temp] && j>i)
j--;//只要a[j]大于基准点继续往前移动j
if(j>i)
a[i++] = a[j];
while(a[i]<=a[temp] && i<j)
i++;
if(i<j)
a[j--] = a[i];
}
a[i] = temp;//基准点元素放到最终位置
quickSort(a,left,i-1);
quickSort(a,i+1,right);
}
快速幂
思路:每一步都把指数分成两半,而相应的底数做平方运算。这样不仅能把非常大的指数给不断变小,所需要执行的循环次数也变小,而最后表示的结果却一直不会变。
例:3^10^ = 3*3*3*3*3*3*3*3*3*3 ,尽量想办法把指数变小来,这里的指数为10。
3^10^=(3*3)(3*3)(3*3)(3*3)(3*3)
3^10^=(3*3)^5^
3^10^=9^5^
此时指数由10缩减一半变成了5,而底数变成了原来的平方,求3^10^原本需要执行10次循环操作,求9^5^却只需要执行5次循环操作,但是3^10^却等于9^5^,用一次(底数做平方操作)的操作减少了原本一半的循环量,特别是在幂特别大的时候效果非常好,例如2^10000^=4^5000^,底数只是做了一个小小的平方操作,而指数就从10000变成了5000,减少了5000次的循环操作。
现在问题是如何把指数5变成原来的一半,5是一个奇数,5的一半是2.5,但是指数不能为小数,因此不能简单粗暴地直接执行5/2,然而,这里还有另一种方法能表示9^5^,9^5^=9^4^*9^1^
此时抽出了一个底数的一次方,这里即为9^1^,这个9^1^先单独移出来,剩下的9^4^又能够在执行“缩指数”操作了,把指数缩小一半,底数执行平方操作。9^5^=81^2^*9^1^
把指数缩小一半,底数执行平方操作,9^5^=6561^1^*9^1^
此时,发现指数又变成了一个奇数1,按照上面对指数为奇数的操作方法,应该抽出了一个底数的一次方,这里即为6561^1^,这个6561^1^先单独移出来,但是此时指数却变成了0,也就意味着我们无法再进行“缩指数”操作了。
9^5^=(6561^0^)(9^1^)(6561^1^)=1(9^1^)(6561^1^)=(9^1^)(6561^1^)=9*6561=59049
能够发现,最后的结果是9*6561。所以能发现一个规律:最后求出的幂结果实际上就是在变化过程中所有当指数为奇数时底数的乘积。
继续优化:
b%2==1可以用更快的“位运算”来代替,例如:b&1。因为如果b为偶数,则其二进制表示的最后一位一定是0;如果b是奇数,则其二进制表示的最后一位一定是1。将他们分别与1的二进制做“与”运算,得到的就是b二进制最后一位的数字了,是0则为偶数,是1则为奇数。例如9是奇数,则9&1=1;而8是偶数,则8&1=0;因此奇偶数的判断就可以用“位运算”来替换了。
m = m / 2也可以用更快的移位操作来代替,例如:6的四位二进制为0110,而6/2=3,3的四位二进制为0011,可以发现,a的一半,结果为a的二进制码向右移一位,即m >>=1。
public static long num(long n, long m, long p) {
long result = 1;
while (m > 0) {
if ((m & 1 ) == 1) {
result = result * n % p;
}
m >>= 1;
n = (n * n) % p;
}
return result;
}
第六章 搜索
全排列
DFS解法
思路:将此过程看做一棵树,每一个结点下都会有 n 个结点表示下一个数,首先先将全部 n^n^ 个结果全部得出,然后剪枝,减去有重复数字出现的情况。
public static void dfs(int depth,String ans,int n){//当前深搜的层数,目前的结果,目标层数
if(depth==n){//当前深搜层数=目标层数
System.out.println(ans);
return;
}
for(int i=1;i<=n;i++){
if(!ans.contains(i+""))//只有当还没有用过i的时候,才会在现在的基础上继续往下拓展
dfs(depth+1,ans+i;n);//进入下一层,ans记录为进入下一层的值,n不变
}
}
BFS解法
思路:先将有重复数字的结果得出,每一个数后都可以跟 n 中可能,那么将这 n 中可能存入队列中,然后重复此过程,直到字符串的长度为 n 时,得到结果;剪枝,如果这个数字已经用过了,就直接只用下一个数字。
public static void bfs(int n){
Queue<String> queue = new LinkedList<>();
for(int i=1;i<=n;i++)
queue.offer(i+"");
while(!queue.isEmpty()){
String now = queue.poll();
for(int i=1;i<=n;i++){//每个结点都向下产生n个结果
if(now.contains(i+""))//i已经使用过了
continue;
String son = head + i;
if(son.length()==n)
System.out.println(son);
else
queue.offer(son);
}
}
}
整数划分
思路:对 n 进行划分后, n 可以被不超过 n 个数累加得到,进行累加的每一个数,也可以被不超过它本身个数累加得到。
public static void dfs(int n,int nowget,int max,String ans){//要划分的数,现在已经得到的值,目前划分已经用到的最大值,具体拆分方法
if(nowget==n){
ans = ans.substring(0,ans.length()-1);
System.out.println(n+"="+ans);
return;
}
for(int i=1;i<=n-nowget;i++){//从nowget累加到n
if(i>=max)//只有当下一个数不小于我之前用过的最大值时,才能保证整个结果为非递减
dfs(n,nowget+i,i,ans+i+"+");
}
}
例题
例题:路径之谜
思路:
1.从入口点开始,到达每一个点都将对应位置北墙和西墙的箭靶数减一,每一个点,都可以继续向四个方向继续前进(前提是这个点没有走过,在城堡范围内,且这个点对应的两个箭靶的数字不为 0 )。
2.如果已经到了终点,就要判断现在每一个箭靶上的数字是否都已经变为 0 ,如果是,那么此时走的路径就是正确解,否则就需要回溯,考虑其他的行走路线。
3.回溯:因为要从已经走过的点退回来,所以在已经走过的点上射的箭要收回,箭靶数加一,并且标记此点为还没有走过。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
public class 路径之谜 {
static int[] path;//记录最终路径,因为底面为n*n,所以走出需要2*n步
static int n;
static int[] cntx;//存储北墙箭靶数字
static int[] cnty;//存储西墙箭靶数字
static boolean[][] visited;//判断此点有没有走过
static int dx[] = {1, 0, -1, 0};//到下一个点x坐标的变化量
static int dy[] = {0, 1, 0, -1};//到下一个点y坐标的变化量
static BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
static PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
public static void main(String[] args) throws IOException {
n = Integer.parseInt(in.readLine());
cntx = new int[n];
cnty = new int[n];
path = new int[n * n];
visited = new boolean[n][n];
String[] s = in.readLine().split(" ");
for (int i = 0; i < n; i++) {
cntx[i] = Integer.parseInt(s[i]);
}
s = in.readLine().split(" ");
for (int i = 0; i < n; i++) {
cnty[i] = Integer.parseInt(s[i]);
}
dfs(0, 0, 0);//从0,0位置开始走,目前走了0步
}
private static void dfs(int x, int y, int step) {
path[step] = y * n + x; //将该点编号记录到路径中
visited[x][y] = true;//将该点标记为已经走过的状态
cntx[x]--;//拔掉对应北墙的箭
cnty[y]--;//拔掉对应西墙的箭
if (x == n - 1 && y == n - 1 && check()){//判断是否到达终点
for (int i = 0; i <= step; i++){//输出答案
System.out.print(path[i]+" ");
}
return;
}
for (int i = 0; i < 4; i++){//上下左右四个方向搜索下一步
int xx = x + dx[i], yy = y + dy[i];
//下一步(xx,yy)未走过且在地图范围内
if (0 <= xx && xx <= n-1 && yy >= 0 && yy <= n-1&& !visited[xx][yy] ){
if (cntx[xx] > 0 && cnty[yy] > 0){//该点对应箭靶上有箭,说明该点可以走
dfs(xx, yy, step + 1);//搜索下一步
//要从xx,yy点回来,在xx,yy点射的箭要复原,并重新标记xx,yy点没有走过
visited[xx][yy] = false;
cntx[xx]++;
cnty[yy]++;
}
}
}
}
private static boolean check() {//判断到达终点时,是否箭靶数都已经归零
for (int i = 0; i < n; i++) {
if (cntx[i] != 0 || cnty[i] != 0)
return false;
}
return true;
}
}
例题:迷宫

思路:从起点开始,将从此点能到达的点存储到队列中,每次获取并删除队列中的第一个元素,并将其能到达且还未到达过的点(若此点已经到达过,则表示当前处理的这条路径不是最短路径)存储到队列中,若已经到达终点,则此路径为最短路径。如果队列中已经没有元素,但仍未到达迷宫终点,则表示此迷宫无解
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.util.LinkedList;
import java.util.Queue;
public class 迷宫 {
static int num;//存储迷宫最短路径所需要的步数
static int xsize = 30;//迷宫大小30行50列
static int ysize = 50;
static char[][] arr = new char[xsize][ysize];//存储迷宫:0表示路,1表示墙
static boolean[][] help = new boolean[xsize][ysize];//判断此点是否已经做过
static int[][] dir = {{1,0},{0,-1},{0,1},{-1,0}};//四个方向横纵坐标的变化量
static char[] sign = {'D','L','R','U'};//表示四个方向
public static void main(String[] args) throws IOException {
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
for(int i=0;i<xsize;i++){
arr[i] = in.readLine().toCharArray();
}
out.println(bfs());
out.print(num);//额外输出最短路径需要多少步
out.flush();
}
private static String bfs() {
Queue<Node> list = new LinkedList<>();//队列
int x = 0;
int y = 0;
int runnum = 0;
list.add(new Node(x,y,"",runnum));//将起点存储到队列中
while(!list.isEmpty()){//判断队列是否为空,若为空,则此迷宫没有通路
Node now = list.poll();//获取队列中的第一个元素并删除
help[now.x][now.y] = true;//将此点标记为已经走过
for(int i=0;i<4;i++){//循环四次,对四个方向进行处理
int xx = now.x + dir[i][0];//移动后的x坐标
int yy = now.y + dir[i][1];//移动后的y坐标
//此点在迷宫范围内,未走过,不是墙
if(check(xx,yy) && help[xx][yy]==false && arr[xx][yy]=='0'){
list.add(new Node(xx,yy,now.num + sign[i],now.runnum + 1));//将此点存入队列中
if(xx==xsize-1 && yy==ysize-1){//如果已经到了迷宫终点
num = now.runnum + 1;//所需步数+1(now.runnum是到达迷宫终点前一步所需要的步数)
return now.num + sign[i];//返回通过迷宫的方式
}
}
}
}
return "";//空字符串,表示此迷宫无通路
}
private static boolean check(int xx, int yy) {//判断此点是否在迷宫范围内
return xx>=0 && yy>=0 && xx<xsize && yy<ysize;
}
static class Node{
int x;//x坐标
int y;//y坐标
int runnum;//到达此点最短步数
String num;//到达此点的方式
public Node(int x, int y,String num ,int runnum) {
super();
this.x = x;
this.y = y;
this.num = num;
this.runnum = runnum;
}
}
}
第七章 贪心
基本概念
所谓贪心算法是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,它所做出的仅仅是在某种意义上的局部最优解。 贪心算法没有固定的算法框架,算法设计的关键是贪心策略的选择。必须注意的是,贪心算法不是对所有问题都能得到整体最优解,选择的贪心策略必须具备无后效性(即某个状态以后的过程不会影响以前的状态,只与当前状态有关。
例题
例题:合并果子

思路:
1.要保证最终耗费的体力最小,那么就可以每次合并都把目前数量最少的两堆果子合并,耗费的体力就是这两堆果子树木的和,然后合并后又可以作为新的一堆果子继续去判断,直到最终只剩一堆。
2.可以借助PriorityQueue优先队列,队列中第一个元素就是最小值,即可每次获取队列中前两个元素,然后将他们的和再次添加至队列中,直到最终队列中只剩一个元素。
3.以题目样例为例:对于数组{pi}={1, 2, 9},Huffman树的构造过程如下:
3.1找到{1, 2, 9}中最小的两个数,分别是 1 和 2 ,
3.2从{pi}中删除它们并将和 3 加入,得到{3, 9},体力消耗为 3 。
3.3找到{3, 9}中最小的两个数,分别是 3 和 9 ,
3.4从{pi}中删除它们并将和 12 加入,得到{12},费用为 12 。
3.5现在,数组中只剩下一个数12,构造过程结束,总费用为3 + 12 = 15。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.util.PriorityQueue;
import java.util.Scanner;
import java.util.Spliterator;
public class Main {
public static void main(String[] args) throws IOException{
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
int n = Integer.parseInt(in.readLine());
long sum = 0;
PriorityQueue<Long> queue = new PriorityQueue<>();
String[] s = in.readLine().split(" ");
for(int i=0;i<s.length;i++) {
queue.add(Long.parseLong(s[i]));
}
long number = 0;
while(queue.size()!=1) {
long a = queue.poll();//获取最小的一堆
long b = queue.poll();//获取最小的一堆
number = number + ( a + b );//合并这两堆耗费的体力
queue.add((a+b));//将合并后的结果放回优先队列中
}
System.out.println(number);
}
}
第八章 树
树的相关概念
什么是树
树(Tree)是 n ( n ≧ 0 )个结点的有限集。n=0时称为空树。在任意一颗非空树中:有且仅有一个特定的称为根的结点。当n>1时,其余结点可分为 m ( m > 0 ) 个互不相交的有限集T1、T2、T3……、Tm,其中每个集合本身又是一棵树,并且称为根的子树。
树的基本概念
二叉树
什么是二叉树
二叉树是n(n>=0)个结点的有限集合,该集合或者为空集(空二叉树)、或者由一个根结点和两颗互不相交的、分别称为根结点的左子树和右子树的二叉树组成。
二叉树的特点
1.二叉树中每个结点最多有两颗子树,度没有超过2的。
2.左子树和右子树是有顺序的,不能颠倒。
满二叉树
在二叉树中,所有的分支节点都有左子树和右子树,并且所有的叶子都在同一层。
完全二叉树
1.叶子结点只能出现在最下面两层。
2.最下层的叶子一定集中在左部连续位置。
3.倒数第二层,若有叶子结点,一定在右部连续位置。
4.如果结点度为1,则该结点只有左孩子。
5.同样结点的二叉树,完全二叉树的深度最小。
二叉树的创建和嵌套打印
//结点类
public class TreeNode{
int data;//结点存放的数据
TreeNode left;//左孩子
TreeNode right;//右孩子
public TreeNode(int data,TreeNode left,TreeNOde right){
this.data = data;
this.left = left;
this.right = right;
}
}
import java.util.Scanner;
public class Tree{
TreeNode root;//整棵树的根节点
Scanner sc = new Scanner(System.in);
public Tree(){
root = null;
}
public TreeNode createBinaryTree(){//树的创建
TreeNode t;//当前树的根节点
int x = sc.nextInt();
if(x==0) t=null;
else{
t = new TreeNode();
t.data = x;
t.left = createBinaryTree();
t.right = createBinaryTree();
}
return t;
}
public void printTree(TreeNode t){//树的打印
if(t!=null){
System.out.print(t.data);
if(t.left!=null || t.right!=null){
System.out.print("(");
printTree(t.left);
if(t.right!=null) System.out.print(",");
printTree(t.left);
System.out.print(")");
}
}
}
}
前中后序层次遍历
前序遍历
思路:对于每个结点,优先处理结点本身,再处理它的左孩子,最后处理它的右孩子。
public void preOrder(TreeNode root){
if(root!=null){
System.out.print(root.data+" ");
preOrder(root.left);
preOrder(root.right);
}
}
中序遍历
思路:对于每个结点,优先处理它的左孩子,再处理它本身,最后处理它的右孩子。
public void midOrder(TreeNode root){
if(root!=null){
midOrder(root.left);
System.out.print(root.data+" ");
midOrder(root.right);
}
}
后序遍历
思路:对于每个结点,优先处理它的左节点,再处理它的右节点,最后处理它本身。
public void postOrder(TreeNode root){
if(root!=null){
postOrder(root.left);
postOrder(root.right);
System.out.print(root.data+" ");
}
}
层次遍历
思路:广度优先搜索;处理根节点的每一个子结点,再处理子结点的每一个子结点......直至结束。
public void levelOrder(TreeNode t){
Queue<TreeNode> queue = new LinkedList<>();
if(t==null) return;
queue.offer(t);
while(!queue.isEmpty()){
TreeNode head = queue.poll();
System.out.print(head.data);
if(head.left!=null)
queue.offer(head.left);
if(head.right!=null)
queue.offer(head.right);
}
}
求二叉树深度
public int treeDepth(TreeNode root){
if(root==null) return 0;//此结点不存在
return Math.max(treeDepth(root.left),treeDepth(root.right))+1;
}
求二叉树叶子结点个数
public int TreeLeaf(TreeNode root){
if(root==null) return 0;
if(root.left==null && root.right==null) return 1;//此结点没有孩子,表示此结点为叶子结点
else return treeLeaf(root.left) + treeLeaf(root.right);
}
重建二叉树
思路:
1.前序遍历为:根,{左子树},{右子树};可得,前序遍历的第一个结点为根结点;
2.中序遍历为:{左子树},根,{右子树};可得,结点的左侧为它的左孩子树,右侧为它的右孩子树;
3.重复此过程,重建此二叉树;
public static String f(String pre,String mid){//前序遍历结果,中序遍历结果
if(pre.length()==0) return "";
else if(pre.length==1) return pre;
else{
int pos = mid.indexOf(pre.charAt(0));
String left = f(pre.substring(1,pos+1),mid.substring(0,pos));
String right = f(pre.substring(pos+1),mid.substring(pos+1));
return left+right+pre.charAt(0);
}
}
第九章 图
第十章 动态规划
LCS 最长公共子序列
思路:
1.用一个数组 dp[ i ][ j ] 表示 S 字符串中前 i 个字符与 T 字符串中前 j 个字符的最长上升子序列,那么 dp[ i+1 ][ j+1 ] 就是S 字符串中前 i+1 个字符与 T 字符串中前 j+1 个字符的最长上升子序列;
2.如果此时 S 中的第 i+1 个字符与 T 中的第 j+1 个字符相同,那么 dp[ i+1 ][ j+1 ] = dp[ i ][ j ] + 1;
3.如果此时 S 中的第 i+1 个字符与 T 中的第 j+1 个字符不同,那么 dp[ i+1 ][ j+1 ] = Math.max ( dp[ i+1 ][ j ] , dp[ i ][ j+1 ] );
public static int LCS(String s,String t){
int[][] dp=new int[s.length()+1][t.length()+1];
for(int i=1;i<=s.length();i++){
for(int j=1;j<=t.length();j++){
if(s.charAt(i-1)==t.charAt(j-1))
dp[i][j]=dp[i-1][j-1]+1;
else
dp[i][j]=Math.max(dp[i][j-1],dp[i-1][j]);
}
}
return dp[len1][len2];
}
迷人的链表(bushi)
今天开始算法专栏,从链表开始,每日一栏 if not now,when? if not me,who? 此时此刻,非我莫属!
算法的基础是数据结构,数据结构的基础是创建 + CURD
什么是链表?
顾名思义,链表就是一个链状表,是一种常见的基础的数据结构,是一种线性表,但是无序,因此,插入时间复杂度是O(1),查找的话,需要遍历,时间复杂度为O(n)。
为什么会存在链表这个数据结构呢?
因为数组的声明需要声明数据空间大小,于是链表这一个不用声明大小的数据结构就出来了,优点就是可以充分利用计算机存储空间,实现内存动态管理;缺点就是失去了数组随机读取的功能,同时链表还增加了结点指针,增加了空间开销。
链表的分类?
链表又划分为单向链表、双向链表、循环链表以及不常见的块状链表。
不再赘述,见维基百科:

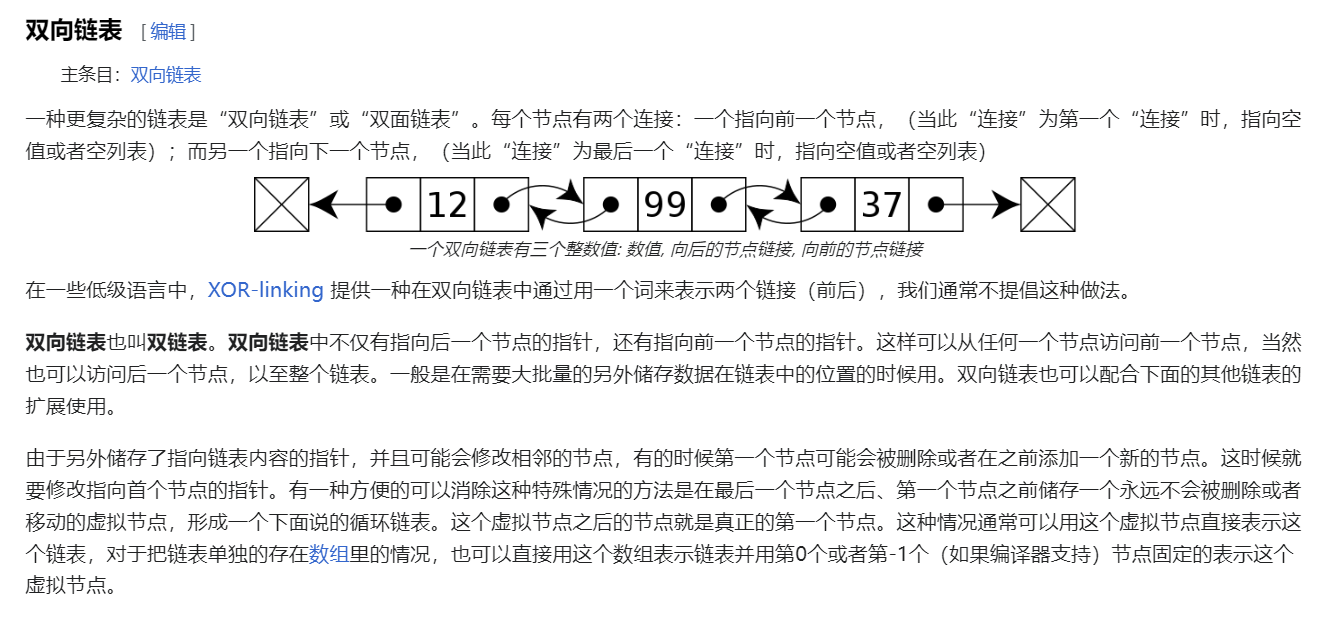



链表的创建
Java 中规范的链表创建方法:
public class ListNode {
private int data;
private ListNode next;
public ListNode(int data) {
this.data = data;
}
public int getData() {
return data;
}
public void setData(int data) {
this.data = data;
}
public ListNode getNext() {
return next;
}
public void setNext(ListNode next) {
this.next = next;
}
}
或许有点过于麻烦了,我们看力扣中是怎么定义的:
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
还有一种常见的定义,经常用于算法比赛中:
public class ListNode {
public int val;
public ListNode next;
ListNode(int x) {
val = x;
//这个一般作用不大,写了会更加规范
next = null;
}
}
ListNode listnode=new ListNode(1);
ok,以上就是链表的创建了。
链表的CRUD
先来链表的查询,也就是链表的遍历
public static int getListLength(Node head){
int length = 0;
Node node = head;
while(node != null) {
length++;
node = node.next;
}
return length;
}
链表的插入
分三种情况,分别是从链头插入、中间插入、链尾插入
- 链头插入
Node node = head;
node.next = head;
head = node;
-
中间插入 中间插入要注意一个顺序,就是不能使链表断开; 正确的顺序应该是先new.next = node.next; 然后node.next = new;
-
尾部插入
美团24春招笔试一笔
题目分布
共5个编程题
题目
Q1:

Q2:

我的题解:
package leetcode;
import java.util.ArrayList;
import java.util.Scanner;
// 注意类名必须为 Main, 不要有任何 package xxx 信息
public class Main1 {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
long cnt = 0;
long cnt0 = 0;
ArrayList<Integer> list = new ArrayList<>();
// 注意 hasNext 和 hasNextLine 的区别
while (in.hasNextInt()) { // 注意 while 处理多个 case
int n = in.nextInt();
int q = in.nextInt();
for (int i = 0; i < n; i++) {
list.add(in.nextInt());
cnt += list.get(i);
if (list.get(i) == 0) cnt0++;
// System.out.print(list.get(i));
}
for (int i = 0; i < q; i++) {
long l = in.nextLong();
long r = in.nextLong();
System.out.println((cnt + l*cnt0) + " " + (cnt + r*cnt0));
}
}
}
}
春招的第一个笔试,属实有点紧张了,没有想起来用前缀和数组,而是使用了最简单的且浪费效率遍历查询,最终虽然AC了90% ,但是还是超时了,造成没有全AC的原因之一可能还与没有处理[L,R]边界有关!
下面是来自AI的建议:
造成这段代码超时的原因在于: 重复计算:在处理每个查询时,代码都会遍历整个数组来重新计算总和cnt和0的个数cnt0。对于多个查询,这种做法会> 导致大量的重复计算。 无效操作:对每个查询范围内的元素并未进行任何针对性的计算,而是直接使用全局累计的cnt和cnt0进行求解。这种方> 式无法正确处理区间内包含0的情况,因为在计算结果时未剔除区间内的0的影响。 为了优化这个问题,应当在读取输入数组之后,预先计算出所有非零元素的累加和(可以采用前缀和的方法),同时记录> 每个位置之前连续非零元素的累加和。这样,在处理查询时,可以直接根据前缀和计算出给定区间的非零元素之和,从而> 避免重复计算并提高效率。
Q3:

Q4:

说明 第一个方案,删除[3]。 第二个方案,删除[4]。 第三个方案,删除[3,4]。 第四个方案,删除[2]。
Q5:

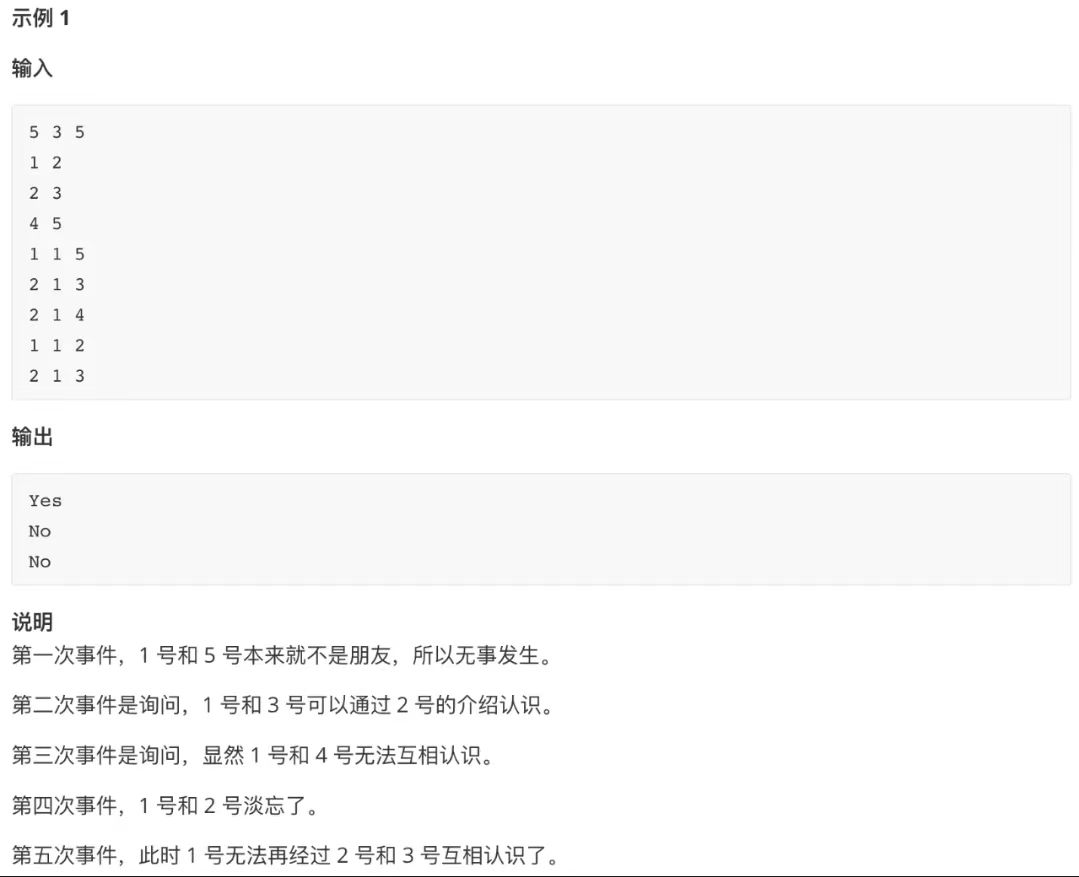
整体体验很好,给了两次机会,两次笔试取最好成绩。
美团24春招笔试二笔
题目分布
共5个编程题,还有两个未截图
题目
Q1:
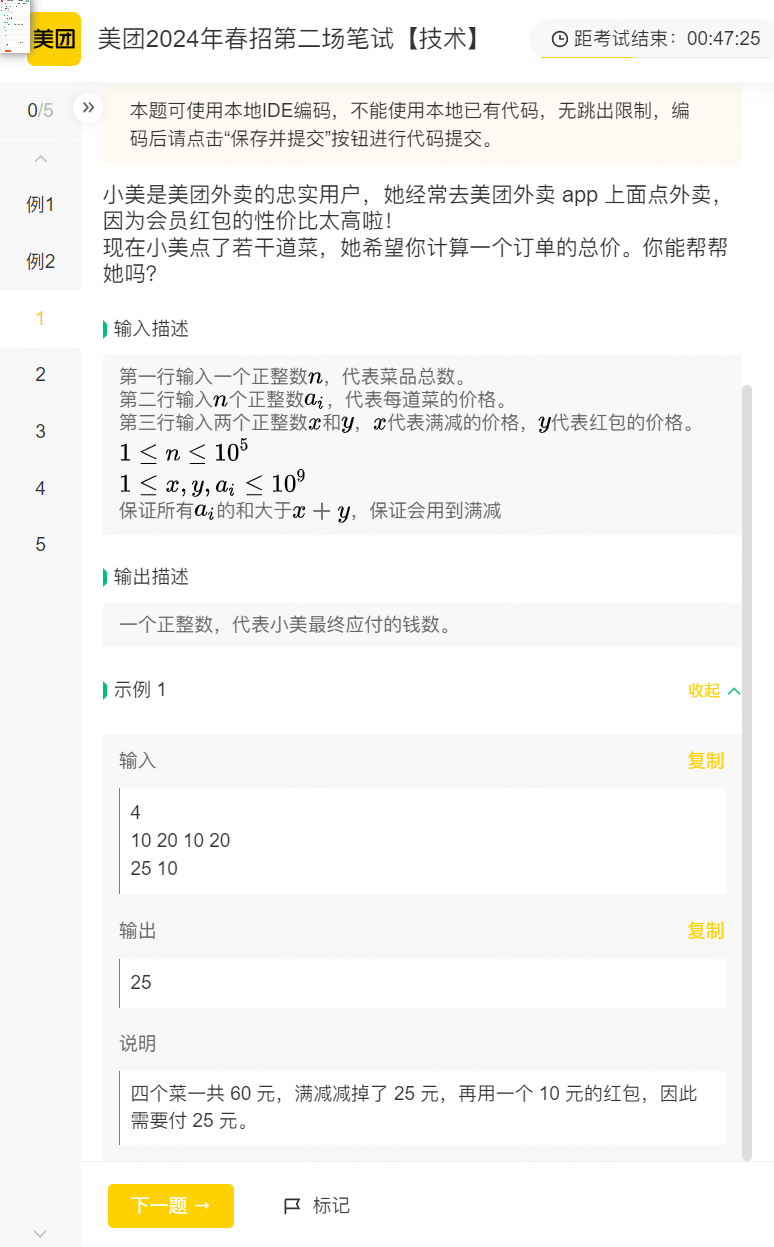
Q2:
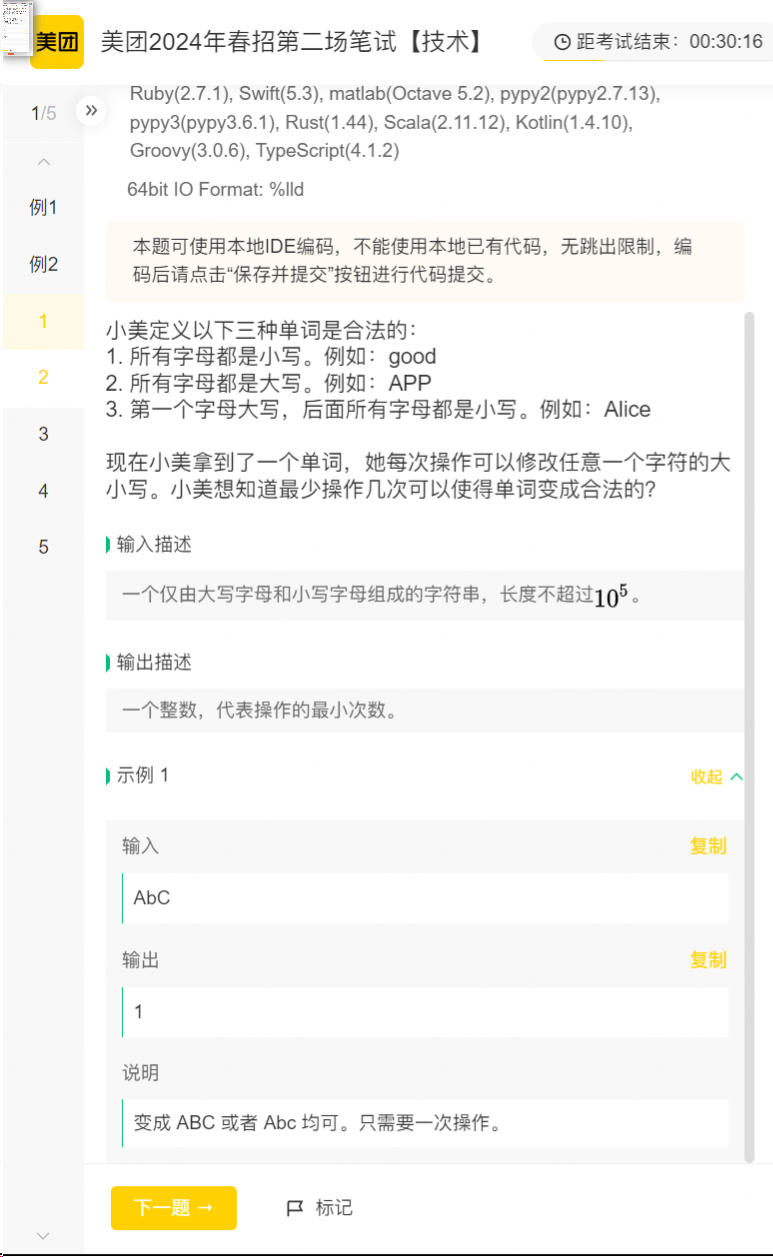
Q3:
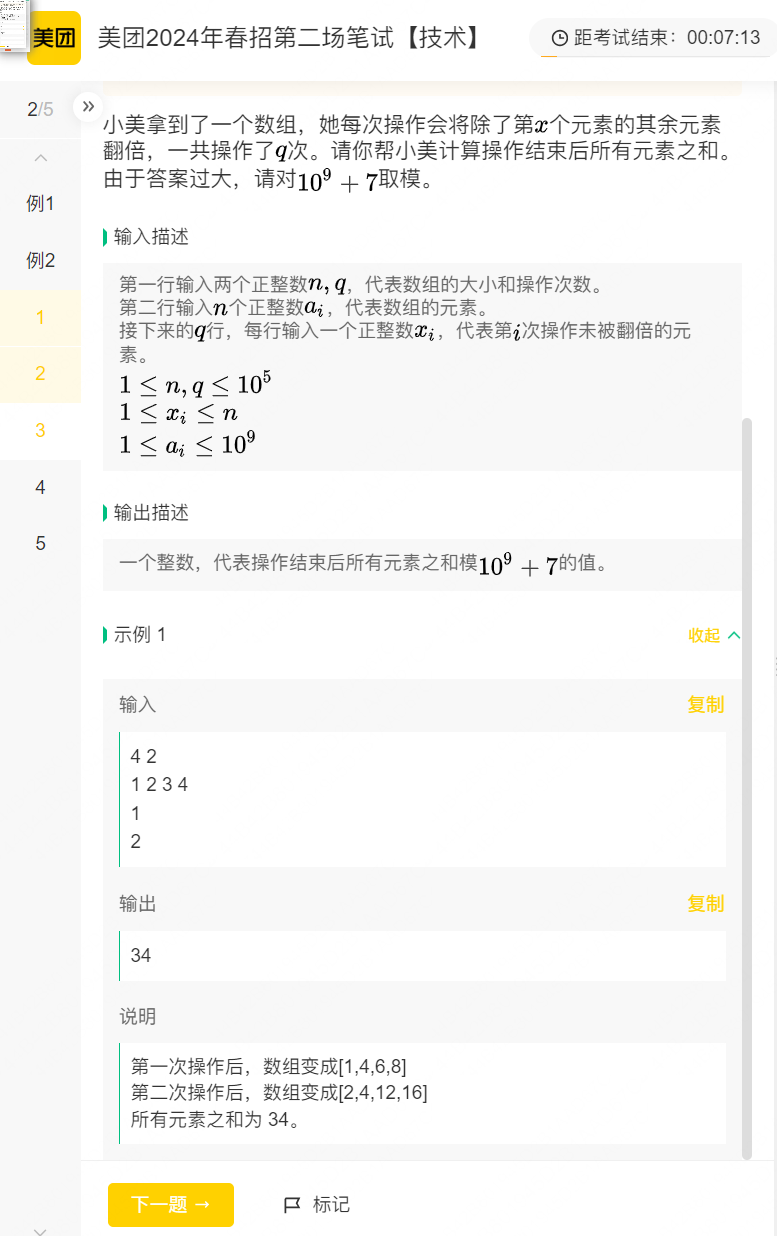
春招第二笔
美团直接5道编程题,但是整体难度偏中等,汉得还有选择题可以蒙一下🤣,但是编程题直接来了两个二叉树,没刷过呀T_T,反正我是想直接交卷了··· ···
第一道“母夜叉”:
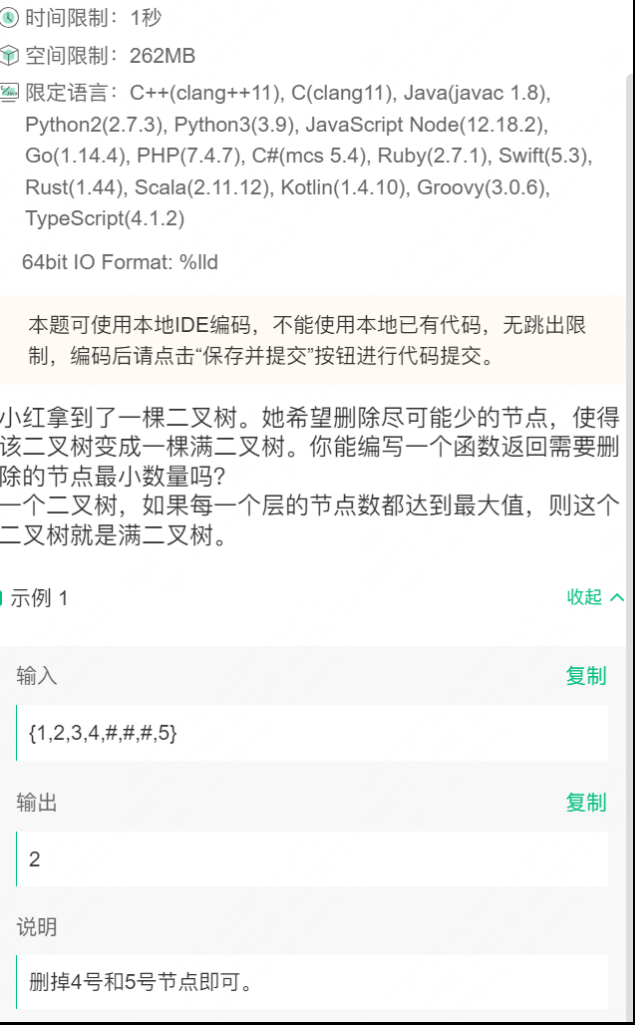
第二道“母夜叉”:
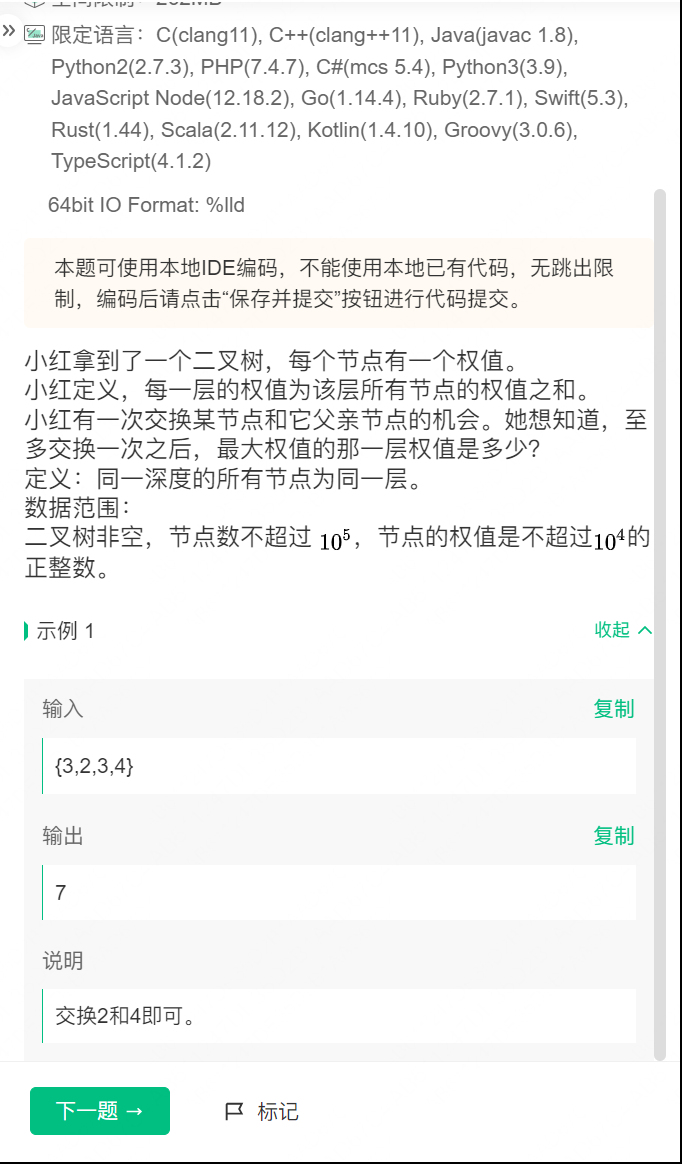
感兴趣的话可以试一试!
春招第一笔
题目分布
共15个选择题、6个问答、3个编程
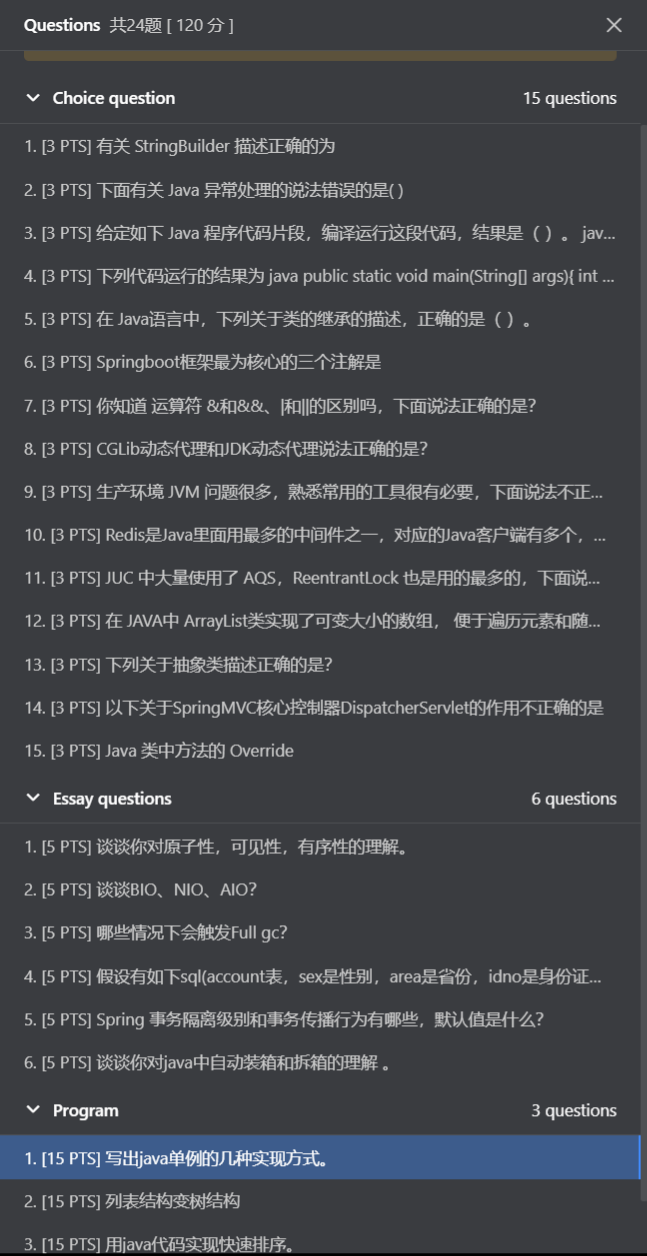
题目
问答Q1:
首先,这三个特性都是线程安全的三个提现。 其次,原子性就是线程之间互斥访问,同一时间,只能有一个线程在进行操作,比如锁、synchronized、CAS算法; 可见性就是如果同一内存中一个线程做出了修改操作,那么对于其他线程来说也都是同步可见的; 有序性就是Hapens-before算法,即我们不需要关注顺序,因为 JVM 内部会进行顺序打乱,所以无需关注顺序。
问答Q2:
BIO(Blocking IO):同步阻塞IO NIO(NonBlockingIO):同步不阻塞IO AIO(asynchronousIO):异步不阻塞IO
BIO就相当于一个链接一个线程,发起请求会一直阻塞,可以通过连接池来改善; NIO就相当于多个连接复用一个线程,一个请求一个线程(我的理解是BIO+连接池); AIO就是一个有效请求一个线程,IO发起请求,立马响应,操作结束后,异步回调通知结果。
问答Q3:
当空间不足的时候会触发。 1,旧生代空间不足 2,Minor GC 空间不足,低于旧生代空间内存 3,perm gen空间存放 class 信息满
问答Q4:
显而易见,此表中并没有合适的字段作为索引。因为性别、省份区分度不大,不适合索引,然而身份证号长度太长,作为索引效率不高,没有必要。
我的索引优化思路: 新增一个字段,比如可以截取身份证后几位,或者通过一些哈希算法对idcard进行运算,得到一个新字段,然后把这个不易重复的字段作为唯一索引。
问答Q5:
隔离级别: ISOLATION_DEFAULT默认隔离级别 ISOLATION_READ_UNCOMMITED修改时可读(出现幻读) ISOLATION_READ_COMMITED修改后才可读(避免幻读) ISOLATION_REPEATABLE_READ防止脏读 ISOLATION_SERIALIZABLE(完美隔离级别)
事务传播行为: 默认为propagation.REQUIRED,如果当前存在事务,就加入,不存在就创建
问答Q6:
自动装箱与自动拆箱是 Java 的语法糖之一。 简单来说,自动装箱就是将 Java 的基本数据类型转换为对应的对象,比如 int 转换为 Integer,float 转换为 Float;反之,自动拆箱就是讲对应类型的对象重新转换为基本类型。 其中,通过我的研究,发现反编译之后的代码,自动装箱的原理是这样的: int i = 5; Integer n = Integer.valueOf(i); 自动拆箱原理: Integer i = 5; int n = i.intValue();
编程Q1:
几种常见的单例模式:
// 懒汉模式————先不创建单例,用的时候再创建
public class Singleton {
private static Singleton instance;
private Singleton() {}
public static synchronized Singleton getInstance() {
if(instance == null) {
instance = new Singleton();
}
return instance;
}
}
// 饿汉模式————立即创建单例,因此线程安全
public class Singleton {
private static Singleton instance = new Singleton();
private Singleton() {}
public static Singleton getInstance() {
return instance;
}
}
public class Singleton {
private static Singleton instance = null;
static {
instance = new Singleton();
}
private Singleton() {}
public static Singleton getInstance() {
return this.instance;
}
}
// 静态内部类
public class Singleton {
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
private Singleton() {}
public static final Singleton getInstance() {
return SingletonHolder.INSTAMCE;
}
}
// 枚举
public enum Singleton {
INSTANCE;
public void whateverMethod() {
···
}
}
简单实现一下单例模式的调用:
package eqianbao;
/**
* 模拟一下单例模式的调用(以懒汉模式为例)
* @Author <a href="https://github.com/wl2o2o">程序员CSGUIDER</a>
* @From <a href="https://wl2o2o.github.io">CSGUIDER博客</a>
* @CreateTime 2024/3/10
*/
public class SingletonLazy {
private static SingletonLazy instance;
private SingletonLazy(){}
// 注意看这里用了同步锁
public static synchronized SingletonLazy getInstance() {
if (instance == null) {
instance = new SingletonLazy();
}
return instance;
}
public void say() {
System.out.println("i'm lazyPeople!");
}
public static void main(String[] args) {
SingletonLazy instance = SingletonLazy.getInstance();
instance.say();
}
}
懒汉单例模式其实是线程不安全的,因为懒汉模式没有事先创建单例,所以我在创建单例的时候加上了同步锁,通过同步锁的同步互斥访问来达到线程安全的目的。更常用的方法还有双重检查锁(Double-Check-Lock),代码如下:
public class SingletonLazy {
private static SingletonLazy instance;
private SingletonLazy(){}
public static SingletonLazy getInstance() {
// 双重校验锁
if (instance == null) {
synchronized (SingletonLazy.class) {
if (instance == null) {
instance = new SingletonLazy();
}
}
}
return instance;
}
}
如果我放任不管呢?是如何线程不安全的?诶我就不加锁,就是玩!就是玩!就是玩!show me your code!
public class SingletonLazy {
private static SingletonLazy instance;
private SingletonLazy(){}
// 注意看!这里没有!!!同步锁!
public static SingletonLazy getInstance() {
if (instance == null) {
instance = new SingletonLazy();
}
return instance;
}
public void say() {
System.out.println("i'm lazyPeople!就是玩!");
}
public static void main(String[] args) {
SingletonLazy instance = SingletonLazy.getInstance();
instance.say();
}
}
最终经过多种情况尝试,发现不加同步锁的懒汉单例模式并没有创建多个单例,可能因为现代 JVM 的内存模型、内部优化 和 CPU 之间的通信方式,通过短时间循环和简单线程池模拟并不能体现出创建了多个单例,线程调度的不确定性仍然存在。
所以,我们需要了解这句话:非线程安全单例模式在某些情况下可能导致多个实例。因此总结一下,没有同步锁,不一定不安全;有同步锁,一定安全。
下面的代码是我想复现一下懒汉单例模式如果不加同步锁的情况下,多线程会创建多个instance,这样就违背单例的概念了,但是模拟代码均未实现创建多例的情况,具体原因如上述描述↑
模拟实现不加同步锁,会创建多例的情况代码:
// 创建多个线程
public static void main(String[] args) {
for (int i = 0; i < 3; i++) {
new Thread(() -> {
UnsafeLazySingleton instance = UnsafeLazySingleton.getInstance();
instance.say();
System.out.println(instance.hashCode());
}).start();
}
}
// 增加循环次数,并让线程休息一会,模拟更加真实的场景
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 900; i++) {
new Thread(() -> {
UnsafeLazySingleton instance = UnsafeLazySingleton.getInstance();
instance.say();
System.out.println(instance.hashCode());
}).start();
Thread.sleep(1000);
}
}
// 上述发现进程执行的太快,睡一睡发现还是获取的单例哈希值,继续优化,加上了 thread.join()
public static void main(String[] args) throws InterruptedException {
final int LOOP_COUNT = 100; // 设置循环次数
for (int i = 0; i < LOOP_COUNT; i++) {
Thread thread = new Thread(() -> {
UnsafeLazySingleton instance = UnsafeLazySingleton.getInstance();
instance.say();
System.out.println("Thread ID: " + Thread.currentThread().getId());
System.out.println("Hash Code: " + instance.hashCode());
});
thread.start();
thread.join(); // 等待每个线程执行完毕,确保输出顺序清晰
}
}
// 不行还是不行,使用线程池试一下
public static void main(String[] args) throws InterruptedException, ExecutionException {
final int LOOP_COUNT = 1000; // 设置循环次数
ExecutorService executor = Executors.newFixedThreadPool(10); // 创建一个固定大小的线程池
// Future<Integer>:executor.submit()通过 lambda 表达式提交 instance 的哈希值,存放于 Future<Integer> 中
List<Future<Integer>> futures = new ArrayList<>();
Random random = new Random();
for (int i = 0; i < LOOP_COUNT; i++) {
Future<Integer> future = executor.submit(() -> {
UnsafeLazySingleton instance = UnsafeLazySingleton.getInstance();
instance.say();
return instance.hashCode();
});
futures.add(future);
// 在这里添加一些随机延时以增加并发冲突的可能性
Thread.sleep(random.nextInt(10)); // 随机等待时间(单位:毫秒)
}
// 遍历取出哈希值
for (Future<Integer> future : futures) {
System.out.println("Hash Code: " + future.get());
}
// 关闭线程池
executor.shutdown();
}
等等,绝对不可能,今天的我发现了昨天很傻的我,我发现了问题所在!用
STAR原则来分析一下:
- Situation(情景):懒汉单例模式不是线程安全的
- Task(任务):模拟实现(证明)线程不安全
- Action(行动):通过拆分分析代码,只有当多个线程同时发现当前实例为空时,才会
new新的实例,因此增加线程冲突率,减少循环次数(多次循环会堵塞) - Result(结果):去掉线程间睡眠时间、减少为两个循环,以此增加碰撞率,提高了创建多例可能性
package singletondesignpattern;
/**
* @Author <a href="https://github.com/wl2o2o">程序员CSGUIDER</a>
* @From <a href="https://wl2o2o.github.io">CSGUIDER博客</a>
* @CreateTime 2024/3/12
*/
public class NonThreadSafeSingleton {
private static NonThreadSafeSingleton instance;
private NonThreadSafeSingleton() {}
// 注意:这里没有加锁,所以是线程不安全的
public static NonThreadSafeSingleton getInstance() {
if (instance == null) {
// 在多线程环境下,两个线程可能同时发现 instance 为 null,并各自创建一个实例
instance = new NonThreadSafeSingleton();
}
return instance;
}
@Override
public String toString() {
return "NonThreadSafeSingleton@" + Integer.toHexString(hashCode());
}
public static void main(String[] args) {
// 创建两个并发线程来获取单例
for (int i = 0; i < 2; i++) {
new Thread(() -> {
System.out.println("Thread " + Thread.currentThread().getName() + ": " + NonThreadSafeSingleton.getInstance());
}).start();
}
}
}
模拟成功截图:
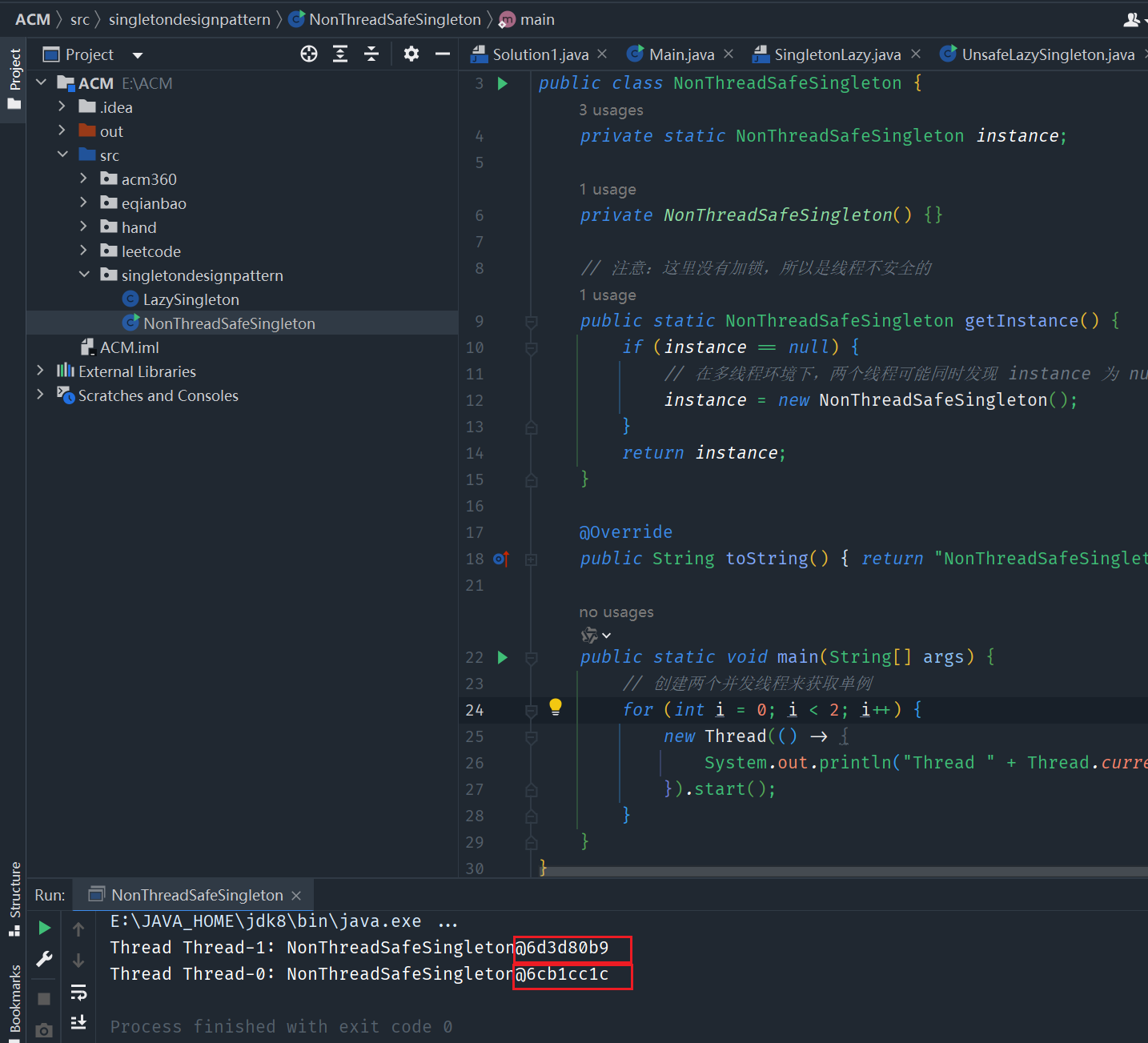
模拟实现加同步锁,一定安全代码:
按照上述方法加上synchronized同步锁关键字,或者使用双重校验锁,也或者可以使用ConcurrentHashMap,都可以解决线程安全问题。
以ConcurrentHashMap为例:
public class ConcurrentSingleton {
private static ConcurrentHashMap<String, ConcurrentSingleton> map = new ConcurrentHashMap<>();
private static final String KEY = "key";
private ConcurrentSingleton() {}
public static ConcurrentSingleton getInstance() {
return map.computeIfAbsent(KEY, k -> {
ConcurrentSingleton instance = new ConcurrentSingleton();
return instance;
});
}
@Override
public String toString() {
return "ConcurrentSingleton@" + Integer.toHexString(hashCode());
}
public static void main(String[] args) {
for (int i = 0; i < 2; i++) {
new Thread(() -> {
System.out.println("Thread " + Thread.currentThread().getName() + ": " + ConcurrentSingleton.getInstance());
}).start();
}
}
}
实现线程安全的单例模式还有很多种方式,比如:
- 使用饿汉式单例模式,
- 使用静态内部类,
- 使用双重校验锁,
- 使用枚举类,
- 使用
synchronized关键字, - 使用
ConcurrentHashMap, - 使用
ThreadLocal, - 使用
volatile关键字, - 使用
AtomicReference, - 使用
Unsafe, - 使用
JUC的AtomicReference, - 使用
JUC的AtomicStampedReference, - 使用
JUC的AtomicMarkableReference, - 使用
JUC的AtomicReferenceArray,
总结
总之,实现相对线程安全的单例模式方法有很多,但是,无论怎么实现,都必须保证只有一个实例,而且必须是线程安全的。
其实,为了保证线程安全,很多方法,都要写很多代码,代码极其臃肿。那么,有没有一种方法,可以保证线程安全,又可以保证代码精简呢?
其实,最简单的单例模式实现方式其实是枚举··· ···
欢迎来到 OS 篇😎😎😎
OS
docker相关
# 拉取镜像
$ docker pull [镜像名称] [版本]
# 查看已安装镜像
$ docker images
# 创建和启动容器,因为懒的配置,所以使用默认配置
$ docker run -itd --name redis -p 6379:6379 redis
# 查看运行中的CONTAINER
$ docker ps -a
# 进入指定的容器
$ docker exec -it mymongo /bin/bash
# 设置 docker 运行时容器自启动
$ docker update redis --restart=always
# 查看docker 运行状态
$ systemctl status docker
# docker重启命令
$ systemctl restart docker
# 容器重启命令
$ docker restart redis(自己命的名字或者CONTAINER ID)
# 删除容器命令
$ docker rm [容器名]
# 删除镜像
$ docker rmi [镜像名]
Docker安装MySQL例子:
$ docker pull mysql
# 在宿主机家目录创建用于放配置文件的文件夹
$ mkdir -p /root/docker-mysql/{conf,data,log}
# 在配置文件目录:/root/docker-mysql/conf新建一个my.cnf配置文件,写入下面内容,设置客户端和mysql服务器端编码都为utf8
[client]
default_character_set=utf8
[mysqld]
collation_server=utf8_general_ci
character_set_server=utf8
# 一套组合拳
$ docker run -p 3306:3306 \
--privileged=true \
-v /root/docker-mysql/log:/var/log/mysql \
-v /root/docker-mysql/data:/var/lib/mysql \
-v /root/docker-mysql/conf:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=你的MySQL密码 \
--name mysql \
--restart=always \
-d mysql
$ docker exec -it mysql bash
$ mysql -u root -p
防火墙相关
# 启动
$ systemctl start firewalld
# 关闭
$ systemctl stop firewalld
# 查看状态
$ systemctl status firewalld
$ firewall-cmd --state
# 开机启用
$ systemctl enable firewalld
# 开机禁用
$ systemctl disable firewalld
# 查看端口
$ firewall-cmd --list-ports --zone=public
# 添加端口(永久添加443端口,协议为tcp)
$ firewall-cmd --add-port=443/tcp --permanent
# 删除tcp下的80端口
$ firewall-cmd --remove-port=80/tcp --permanent --zone=public
# 重新加载
$ firewall-cmd --reload
------------------------------------------------------------------------
参数介绍:
firewall-cmd:是Linux提供的操作firewall的一个工具
--permanent:表示设置为持久;
--add-port:标识添加的端口
--remove-port:标识删除的端口
文件和目录操作相关
# ls: 列出当前目录下的文件和子目录
$ ls
# cd: 改变当前工作目录
$ cd [目录路径]
# mkdir: 创建一个新目录
$ mkdir [目录名称]
# rm: 删除文件或目录
$ rm [文件/目录路径]
# cp: 复制文件或目录
$ cp [源文件/目录路径] [目标路径]
# mv: 移动文件或目录
$ mv [源文件/目录路径] [目标路径]
# touch: 创建一个新文件或修改文件的时间戳
$ touch [文件名]
# cat: 查看文件的内容
$ cat [文件路径]
# grep: 在文件中查找指定的字符串
$ grep [要查找的字符串] [文件路径]
# du: 查看目录大小
$ du [目录路径]
# tar: 归档和压缩文件
# 创建 tar 压缩文档
$ tar -czvf [压缩文件名.tar.gz] [要压缩的文件/目录路径]
# 解压 tar 存档文件
$ tar -xzvf [压缩文件名.tar.gz]
系统状态和资源管理
# ps: 查看当前运行的进程
$ ps
# top: 查看CPU和内存使用情况
$ top
# free: 查看内存使用情况
$ free
# df -h: 查看文件系统使用情况
$ df -h
# ssh: 远程登录到另一台主机
$ ssh [用户名]@[主机地址]
# lsof -i: 端口占用情况
$ lsof -i
日志查看相关
# tail: 常用语查看日志文件
$ tail -n [行数] [文件路径]
# 查看实时日志
$ tail -f [文件路径]
# less: 查看大文件的内容,在less中,可以使用Page Up、Page Down、上下方向键等进行滚动和搜索。要退出less,可以使用q键。
$ less [文件路径]
# grep: 在日志文件中查找指定的字符串,eg:grep ERROR /var/log/myapp.log
$ grep [要查找的字符串] [日志文件路径]
校招与面经
声明:本文转载自编程导航公众号,发布于此便于个人学习,侵权删!
写在开头
以下内容是我最近的面试的结果,其中涉猎广泛小中大公司都有~
整个秋招下来也是一个成长的经历,明白了很多各方面关于找 java 工作的信息,下面我会分别从求职信息(信息差)以及面经角度去写,希望也能够打破大家的信息差!
校招流程
- 网申(投简历)
- 测评(看你性格啥的,部分无)
- 笔试(部分实习及小公司无)
- 确认信息(hr面,聊天,部分无)
- 面试(业务岗位面试1-2轮+主管/人事面,沟通什么时候到岗)
- 给 offer
- 签订三方(给你正式员工的 offer)
有些公司整个流程下来贼慢。甚至1-2月,所以做好准备!
关于校园招聘
校招:指校园招聘(学生身份)一般集中在春秋季节,又称春/秋招。
秋招:秋季校园招聘。
春招:春季校园招聘。
offer:录取通知书(注意口头offer有风险)秋招offer一般指的是毕业直接去上班就行了。
签三方:与校园、公司,签订三方。(这个时候才稳!)
关于上述校园招聘信息差
**1、有很多人其实并不了解,校园招聘的重要性。**首先如果你的目标是大厂(要明白大厂不缺人)的话,那么春秋招是大厂招聘学生的唯一途径。(所以不要错过!)
**2、校招的周期很长,做好长期拉锯战的准备。**有时候一家公司的整个招聘流程会长达 1-2 月,所以千万不要认为 2、3 天没给通知就认为自己挂掉了。(注意做好与自身心里对抗的过程,以及脱产的一种压力....比如你在家的话,家庭的压力....你懂的!)
**3、大学生第一份工作很重要。**对你后续跳槽起到决定性作用,所以签三方要注意!举个例子:就算你去的不是耳熟能详的大厂。去一些亚信、用友、金蝶、泛微,个人感觉都要好过于一些不知名的公司。(当然,除非薪资你各方面很满意。)
4、没拿到毕业证,工作都属于实习。
**5、最好的打算是做到暑假实习。**即秋招,就是暑期实习;然后通过一个实习转正去留用。而不是秋招一把梭哈。
6、只有大公司才会校招(这里指的是给开 offer ),小公司不会给开 offer 的。而是通过让你实习,等到你拿到毕业证,然后进行转正。
关于找工作
**1、大学生第一份工作慎重慎重慎重!!!**实习无所谓,正式留用的话尽量去大平台,记住一句话:0-20 人这种公司,一律 pass。
**2、找工作途径要 open。**boss、智联、官网网申都要进行,甚至积攒人脉,让别人内推你。
**3、内推说有用也有用,没用也没用。**有的内推起码可以帮你省掉烦人的测评,甚至于笔试。
**4、部分实习是要求你达到一个期限的。**比如要求你实习3个月,4个月,5个月这样!
5、没面试,没offer,是正常的,心态要放平!
**6、能部门只招就部门直招(实习),不要都在官网投。**比如滴滴、货拉拉(我遇到的)是有部门直招的,当时我直接在 boss 上就面试了,跳过了笔试等环节。
面试环节
聊天
1、为什么投/选择我们公司?了解过我们公司嘛?
在一面信息确认环节遇到的,比如讯和和泛微,当时就瞎说呗....
2、介绍一下你自己
这里给大家一个思路,信息介绍+项目+个人技术栈。
举例:面试官你好!我叫 xx,是一名 xx 大学大四的本科生。因为大四了嘛,所以想要找一份实习工作,在校期间呢,参加过 xx 比赛,拿过 xx 奖。因为我是科班嘛,所以计算机基础相关的学习跟着学校课程来的:比如计算机网络、操作系统,在企业中开发的技术栈,如 SpringBoot,是通过自学的一个途径。
提示:这不重要,有啥说啥也行,我有时候嫌麻烦,就随便说两句,表达流程、不紧张即可。
3、我看你有一段实习经历为什么辞职?怎么不考虑留用?
这个有好几次面试官问到我,感觉也是因为我是一个实习生身份嘛,怕我跑路...
4、你高考成绩多少分?怎么没参加四六级,你不觉得有四六级是一种优势嘛?
(讯和你个对日外包问的什么破问题......)
5、介绍一下你的实习,之前实习做了什么?
当时泛微群面问到的,一起的一共五个人,然后大概有三个人有实习经历。
所以,可能....有实习经历会加分。
java基础
1、java基本数据类型?
八种嘛,最简单的八股了。有手就行,估计面试官也是先从简单的开始,意思一下!
2、封装的数据类型?
就回答了一下,常用的有String、Integer。
3、&& 和 & 区别?
当时第二个没想起来,只回答了第一个是逻辑与运算,然后巴拉巴拉...
4、String()类,的方法?
这问题差点给我弄懵...当时就想起来 valueOf() 然后说了一个 charAt(),(当时我脑子里还在想 length()是不是....)后面又心虚的说不是...然后面试官说别紧张.....
然后面试官就问我比如分割字符串怎么弄,我说 split()
5、String(),StringBuffer(),StringBuilder()区别?
常问八股之一,巴拉巴拉...
6、HashMap,HashSet 的区别?
集合常问八股,巴拉巴拉...
7、ArrayList,LinkedList 的区别?
集合常问八股,巴拉巴拉...
8、HashMap 为什么用红黑树?
归根结底还是问 HashMap。
9、== 和 equals 的区别?
基础常问八股,巴拉巴拉。
MySQL
1、面试官给我几个字段,让我查询班级平均成绩,写 sql?
当时我没想起来AVG(score),我就说有一个关键字。然后,我把这个放在 where 后面了,然后面试官就说这能放在 where 后面嘛?说实话,不上机让我口述还有点紧张,哈哈哈....
2、事务隔离级别知道嘛?ACID 原理。
3、数据库调优有经验嘛?怎么优化?
其实这里有个坑就是,我当时简历写的是熟悉mysql和redis优化.....后来被滴滴面死后我就把简历改了。
4、索引的数据结构?
5、select,id,where,name,is,null,id,是主键,问走不走索引?
6、SQL,语句优化场景,能举例子嘛?从排查到优化。
以上问题反正翻来覆去就是索引呗,所以你懂得!MySQL,索引是必问的。
然后中小的话,可能会问一些简单的,考察一下你基础,比如让写,sql,啥的。
当时我面滴滴,面试官是默认增删改查你都会的!
Redis
1、数据类型?
说实话,亚信挺有意思的,面了两次,一次面试官问你 Java 数据类型,一次面试官问你 redis 数据类型。hhh~
2、你用redis,都是干啥?redis应用场景?
当时先问的应用场景我就从八股的角度说了一下,然后面试官突然来一句你用过 redis 嘛?,给我弄懵了,我说用过用过...然后追问我用来干啥了,当时大脑卡壳了就说了个分布式 ID,最主要的缓存我都没说。hh~
3、了解 scan 嘛?redis 集群怎么搭建?redis 的优化了解过嘛?怎么一键删除大 key?
滴滴上难度了,当时确实也是第一次没啥经验嘛,有点打击到我!虽然后来发现都是一些常见的八股...
并发
1、sync 底层原理。
2、一个什么注解,问我用过嘛?
我说没有,然后面试官说:算了,不重要.....
不重要那你问我......
3、线程池参数,给我出了道题,问我现在是执行什么操作。
框架
1、Mybatis,#,和,$,区别?
这也是常见八股了,我直播还看到过,不过我当时看直播也走神了....,就说了#预处理,$没用过。
2、SpringBoot,常用注解?
面亚信两次,两次面试官都问这个,挺好玩的。
直接从天南说到天北.......
个人认为,判断一个人Spring,熟练度,这一个问题足矣。
3、说一下IOC?
常见八股。
4、自动装配原理?
常见八股了,不过我遇到的那个面试官,老是喜欢通过场景去问你:比如你项目中写了 API 项目,那么就会问你 sdk 怎么做的?sdk 怎么做的,那不就是自动装配原理嘛?所以又绕回来了....
5、a 方法开启事务注解,b 没用,问你 main 调用 a,a 调用 b,事务还生效嘛?
6、spring 配置信息写在哪里?你用 yml,还是那个啥,我说我用 yml。
这问题我觉得挺简单。的而且没搞懂面试官想问的点,不写在 yml 还能写到哪里去....
项目
API调用平台
1、API 调用平台,sdk 怎么简化了开发?用户怎么去调用?你这个 sdk 做了什么功能?sdk 怎么开发的?
sdk 简化了开发,因为用户直接引用 jar 包就能用了,用的时候,直接在 yml 写好配置就行了,sdk 我回答的是加密,sdk 开发回答的是,先这样再那样,顺便提了下自动装配。
2、问我为什么不用@Value,获取值,用 yml?
这我没搞懂,我就说用啥不都行嘛?
3、gateWay,怎么做到的鉴权?
给我问住了....当时那个简历是,老简历了,而且上来问我第二个项目.....
第一个项目我是 BI 项目,第二个是 API 项目,看来面试官这是对 API 项目更感兴趣啊!
然后我就简单的回答了下,我说再 gateway,拦截器里,拦截到,然后又对业务封装了下,然后我说具体的因为项目之前做的,有点忘了。(说之前 gateWay 是通过阅读官方文档自学的嘛,后来就不用了,一些语句语法啥的就忘了,然后说了下过滤请求怎么做到的....)
然后我和面试官就笑了。。。。
BI项目
1、BI 项目,这是干啥的?
两个亚信的面试官都问到了,哎怪不得上来先问我第二个 API 项目。
感情 BI 这么冷门啊,然后就介绍了什么叫 AIGC,回答了下这个项目是干啥的。
2、基于 IO 线程池、自定义线程池怎么做的?线程池作用?
输出线程池的知识,先从 IO,CPU,这两种讲起,然后,又说了核心参数这些,
然后回答这个项目为什么要用啊,怎么异步啊……
3、问我 MQ 干啥了,怎么弄的异步啥的?
回答起到了一个削峰嘛,然后我又说我用的是两种方案,线程池主要是本地的嘛,所以后续引入了 MQ,mq 好处就是他是一个分布式嘛,也便于后续扩展!
异步,巴拉巴拉……
最终面试官:噢~
看着面试官搞明白了我的项目业务流程,
我露出了满意的笑容!
不是因为项目太简单了哦~纯粹是我口才好,对就是这样b( ̄▽ ̄)d
反问
1、回答/表现怎么样?
如果面试官:还行吧,其实你们都差不多这个水平,寄了/(ㄒoㄒ)/~~
如果面试官:还不错。稳了!全都稳了(^_^)
问这个也方便做复盘总结!
2、后续二面的话,需要多长时间?
这个主要不瞎等嘛,毕竟....成年人的世界,不回复就是拒绝了!
3、公司岗位是做什么的/我进去之后干什么内容?
可以知道是不是核心业务或者是不是外包之类。
4、实习生加班嘛?加班有没有加班费?
终面的时候当聊天的时候可以问一问,毕竟不能和钱过不去。
5、后续可不可以转正?转正流程是什么?转正后薪资。
工作不好找,能转就转,你懂的!
6、实习工资多少?工作地点、工作环境?
就当聊天随便问了!工作环境我觉得还是很重要的。
大长桌那种,我真的......受不了!!!
以上:1、2,是必问的。
后面的话,就当聊天时随便问问了,以上那几条算我提供的一些思路吧!
比如,我在反问的时候也问到了我表现怎么样,面试官也说了还不错。
可能这就是为什么后面我在问别的问题的时候,面试官也挺真诚的!
欢迎踏入职场篇😎😎😎
面经
郑州鑫丽锋科技有限公司(招转培--赛码培训)
-
自我介绍,技术栈
-
讲讲你最熟悉的一个项目
-
数据库用的什么? 答:MongoDB 和 Redis
-
用到了Redis 的什么功能?哪些数据需要做缓存?不会有读写不一致问题吗?用的集群还是? 答:用的 Linux
-
支付模块怎么做的?
-
项目比较难的地方有哪些? 答:订单超卖
-
常用的集合有哪些?
-
什么是反射?反射的底层用的什么?
-
Spring 的常用的注解?
-
@Controller 和 @RestController 的区别?
-
MyBatis 中 $ 和 # 的区别?
-
SpringBoot中的 jar 包和普通的 jar 包有什么区别?
-
MySQL 做过哪些优化?怎么查看 sql 中有没有用到索引? 答:EXPLAIN关键字
-
多线程用过吗?
-
Linux 常用命令?怎么查看日志?
-
项目上线了吗?
-
到岗时间,期望薪资?
- ArrayList 和 LinkList区别?
- HashMap 1.8之后新特性?
- MySQL调优
- 介绍项目
2024/6/12
- 在校期间成绩怎么样?
- 实习经历?这期间负责了什么?
- 最近做的一个是什么项目?你负责了哪些模块?数据库用的什么?实现了什么功能?
- 数据库的事务是什么?
- Redis 是用来做什么的?你会用来做什么业务?
- 基于Redis的分布式锁会有什么问题?
- 缓存的击穿、穿透和雪崩讲一下,怎么解决?
- ES 是什么?
- 数据库优化的方法有哪些?分库分表有了解吗?
- 索引什么时候会失效?
- 自我介绍
- Spring 的 IOC 和 AOP 怎么理解?
- 消息队列怎么避免重复消费?
- 怎么解决 git 冲突?
- Redis 的持久化方式?
- 到岗时间?
1、项目中用了哪些东西实现了哪些功能
2、介绍Redis
3、介绍Mybatis-Plus
4、Mybatis-Plus批量更新语句具体怎么写
5、用mybatis时常用的sql标签有哪些
6、for标签里都有哪些属性
7、java常用的数据类型
8、基本类型和包装类型怎么转换,具体怎么装箱拆箱
9、怎么比较基本类型和包装类型的值是否相等
歧飞科技
1、了解过微服务吗,说一下微服务和传统服务之间的区别
2、了解过缓存雪崩和缓存穿透吗
3、讲一下mysql怎么读写分离
4、讲一下mysql建立索引是根据什么
5、讲一下mysql怎么分库分表
6、WebSocket是不是会保证送达
7、后台对营业额统计的数据是实时的吗
8、后台对营业额统计是怎么实现的
9、判断订单是否超时是怎么做的
10、Vue具体了解多少
11、有用Vue套用ElementUI写过页面吗
12、接口工具有时用吗
简短的自我介绍
跨域问题怎么产生的
怎么解决跨域问题
sql语句中where 和 having 的区别
软通动力一面
Linux
-
进入目录命令
-
创建文件、创建文件夹
-
查询日志,实时日志?历史日志
-
启动jar包 && 后台运行 && 打印日志到指定文件命令
-
还了解什么高阶的命令
线程池
- 线程池核心参数有几个?
- 线程提交任务流程
- 线程池任务抛异常了怎么办?
- 核心线程和非核心线程的区别?
集合
-
常见的集合类型有哪些?
-
ArrayList 和 LinkList的区别?
-
hashmap线程安全吗?如果并发使用会有问题吗?
Java基础
-
== 和 equals 的区别?
-
StringBuilder 和 StringBuffer的区别?
MySQL
-
MySQL 的索引是什么数据结构?为什么默认数据机构是B+树?
-
hash索引有什么特点?
-
索引失效场景有哪些?
-
为什么不等于符号也会导致索引失效?
答案
Linux
nohup java -jar 'jar包名' > '日志文件名' &
线程池
- 七个:核心线程、最大线程、空闲时间、时间单位、工作队列、线程工厂、拒绝策略
- 就是有三个容器:核心线程、等待队列(如果满了)、扩张线程池到最大线程数量)
- 一,在可能抛出异常的时候,让调用方能够感知到 二,如果线程没有被处理,线程被回收
- 这个没有绝对的区别,无非就是创建早晚的区别,当有异常时,会被回收,然后线程池创建一个新的线程来替换,线程池本身只会保证创建的线程的数量复合我们的配置,对管理的线程不会有底层区分,所以并没有本质区别
集合
-
常见的集合类型分为两块,一是Collection,分为List、Set、Queen ,二是Map,map又分为hashtable、hashmap、treemap、ConcurrentHashMap
-
ArrayList 和 LinkList的区别?
- 不安全,并发使用会产生
fail-fast机制,抛出异常,解决方法:比较简单的一个方法可以使用hashtable,本质就是给每个方法来了一个syncronized锁,效率比较低; 或者就是使用ConcurrentHashMap(它是乐观锁 + syncronized 来保证线程安全的)
Java基础
-
== 和 equals 的区别?
-
StringBuilder 和 StringBuffer的区别? 链接直达
MySQL
-
索引的数据结构是
B+树,还有hash索引, 但是一般业务开发中使用的大多是B+树,因为实际业务中经常有分组查询、批量查询需求,B+树叶子结点存储了所有数据,使用双向链表链接叶子结点,更加适合业务场景 -
hash数据结构==> (k,v) ==> 查询快 =多快?=> 正常时间复杂度为O(1), 平均速度O(logn) -
四种失效场景:左模糊查询、使用函数、or 查询、不等于符号
-
因为使用不等于符号涉及到MySQL底层的一个优化器策略:会根据索引过滤的数据量进行判断,如果查询出来的数据很多(索引被过滤掉的数据很少),造成了索引失效的效果,但其实这是MySQL底层做的一个优化器策略
数字马力面经
同学 1
时长-35分钟 0 自我介绍
-
怎么学习
-
tcp ip三次握手四次挥手
-
http和https什么区别 https安全交互有什么步骤(不知道)
-
对称性加密,非对称性加密 (不知道)
-
cookie和session的区别
-
实现单例对象有几种方式 这些方式优缺点是啥 为什么懒汉要双重判断?
-
怎么计算两个ArrayList的并集 交集 差集(好像有一些API,当时没答出来)
-
ArrayList和LinkedList区别 优缺点 是不是线程安全,怎么使用一个线程安全的List
-
currentHashMap怎么保证线程安全 1.7 1.8区别
-
怎么理解Hash冲突
-
序列化 反序列化的理解 什么时候需要用到 怎么用 为什么要指定UID 为什么我序列化后插入一个数据后反序列化有什么问题 为什么有这个问题?为什么你说uid不指定就会出现这个问题(这地方不是特别熟,并且有点紧张,说的很差,最后心态直接爆炸,直接说我了解的太少。这里我就不想面了)
-
StringBuffer和StringBuilder说一下
-
Springboot如何获得IOC容器 (都在背八股,太长久了忘了)
-
Springboot加载文件顺序,不在同个目录下呢?
-
用到gateWay是吧。gateWay如何实现url重写(不知道)
-
Feign用过是吧,怎么通过openFeign进行请求头设置(没用过,不会)
-
mybatis # $ 区别
-
maven会用吧,说一下依赖传递性(忘了,说成了继承,被他点着说:我要你说依赖传递,你说的是继承)
-
Spring事务用过吧,原理是什么 静态代理原理是什么?
-
bean加载过程 如何在装配阶段进行bean的替换,复制(md都是背八股,都忘了之前的实操了,回去好好复习了)
-
数据库四大特性 数据库隔离级别 默认隔离级别 RR是不是完全解决幻读?举个没解决幻读的例子
-
MVCC说一下
-
聚集索引 非聚集索引
-
类加载器作用,为什么要通过类加载器进行加载
-
反问
总结:不知道不了解都说烦了,没信心了,直接GG。虽然都是常规的八股,但是加上有点紧张回答的不好,并且面的广度比较大,包括一些ArrayList的API,maven依赖我都很少用,并且有些问题没有说清楚,看你不熟悉就直接往深处一直问,只能说一句不了解不知道来结束这个问题,有些计网的八股还不是很熟。就这样吧,秋招不行我就滚去实习准备春招了,春招不行我就去送外卖。
同学2
数字马力(郑州 java开发) 10/23 笔试 算法三道题
-
哈希表判断重复
-
链表CRUD "insert 1" "delete 0",这种字符串解析对链表CRUD
-
正则表达式匹配 这种题是true/false的,直接全false A 33.6% 全ture A 66.4,先骗一下。后来又用java String的API全A了。
10/28 线上一面(40min) 0. 其他都是常规问题
- AQS源码
- AOP源码
- ConcurrentHashMap源码
- spring的事务传播机制及实现原理
源码部分我都不会,也是我接下来需要补足的。不过面试官非常好,给我说我这边给你过了,不确定你二面能不能过。
10/31 线上二面 0. 果然不堪一击!
面试官很好,是我太菜。
同学3
数字马力 一面
- 先问一些java基础吧,
- Java的Map了解吗,有哪些实现。那CurrentHashMap怎么保证线程安全的?
- 你在使用Map的时候怎么遍历,有哪些遍历的方式,既然Iterator可以遍历,你说说Iterator。
- 多线程有哪些参数,工作中的使用多线程的场景你说一下,有没有遇到什么问题,怎么解决死锁的。
- Spring Bean的生命周期,Spring的Bean为什么默认是单例模式,那减少JVM GC垃圾回收的实例,你说下垃圾回收的一些算法吧,回收过程起死回生这个现象出现在那个阶段。
- RabbitMQ怎么保证程序执行成功消息一定发送成功,消息发送成功消费者消费失败,你有什么补救措施(或怎么处理)。
- Redis缓存,Redis分布式锁,一些场景和应用吧。 mysql优化一些问题等。记不太清了。
ps: 一面问的都比较基础但是会抓着一个点一直问。
同学 4
面经:主要看着简历问的,简历上写知识点的有点忘了,给自己挖坑了
- 讲讲NIO(不会,然后接着问了IO
- 单例模式有哪些实现方式?
- mysql慢查询怎么优化?
- 主从复制原理
- bean的生命周期(忘了
- 了解jvm吗?
- juc包下有哪些类?实际使用?
- 讲讲ReentranLock
- 场景题
- 反问环节。
作者:鼠道难 链接:https://www.nowcoder.com/feed/main/detail/6b65b2fa96f64b2f8c92127702e03775?sourceSSR=search 来源:牛客网
同学 5
数字马力/1面
- jvm的内存结构
- 有哪些类加载器
- 双亲委派机制
- spring的ioc原理
- spring的事物执行原理
- spring aop的底层基于什么实现的
- mysql的主键索引和唯一索引的区别
- mysql底层基于什么实现的
- b+树的运行原理(没答上)
- 做了这么项目最熟悉哪块(挖了个坑,说自己数熟悉线程池,多线程,并发)
- 不用现在的开发工具,你如何去实现一个线程池(回答要有一个队列,他问我为啥要队列,额,说队列不是关键的,麻了,我说起到缓冲的作用,又给自己挖了个坑,mq就是多并发的)
- 那你自己知道mq的consumer是怎么实现并发消费的
- feign和http的区别
- 什么是微服务,cap是什么?
还有一些面试题不记得了,感觉寄了🐔
作者:喜欢后撤步的大老虎觉醒了 链接:https://www.nowcoder.com/feed/main/detail/c20f18e722b24cefbca55f6550ef62c8?sourceSSR=search 来源:牛客网
同学 6
数字马力-Java开发工程师(长沙)- 一面【已过】
- 自我介绍
- 实习项目组做的是什么业务?
- 开发组大概是有多少人?人员分配呢?
- 你做的这些项目都是来源于哪里啊?
- 一个项目大概要做多久?
- 在哪里找的项目?一般通过哪些网站找的?
- 介绍一下API开放平台里面有哪些内容,以及是怎么实现的吗?
- API签名认证算法你是怎么设计的?
- 看你项目中使用异步编排进行解决接口响应慢的问题,那么对于接口响应慢的问题你一般有哪些思路?
- 你的项目中商品的预热是怎么做的?
- 那你一般怎么进行保证数据库与缓存中数据的一致性问题?
- 看你使用过RabbitMQ的延时队列,你知道他的底层是怎么进行实现的吗?
- 分布式锁使用的是Redisson对吧?
- 扩展问一下:处理redis可以实现分布式锁,还有哪些技术栈可以实现分布式锁?
- MYSQL是可以进行实现分布式锁,但是与Redis的实现方式不同,你知道哪里不同吗?
- 还知道哪些技术可以进行实现分布式锁吗?
- 你知道Redisson的看门狗机制是怎么进行实现的吗,为什么可以达成续期?
- 我看你使用了SpringCache相关注解,你能给我介绍一下都有哪些注解吗?
- 这个注解是怎么识别出参数,然后作为key的呢?
- 比如说我在使用SpringCache的注解的时候,参数是一个对象,对象中有很多个属性,如果我们要使用对象中的属性作为key,那么我们该如何进行指定,才能让SpringCache注解识别到对象其中的属性?
- 你知道EL表达式有哪些解析方式吗?
- 你知道Spring对EL表达式有哪些支持吗?
- 你知道EL表达式除了在SpringCache注解中使用到了,还在哪里使用到了El表达式吗?
- ThreadLocal是用于存储登录态的哈?为什么要使用ThreadLocal啊,有相关的技术栈的考量吗(理由)?
- 最后你会进行threadLocal的清除吗?
- 如果现在是一个分布式项目,想要实现ThreadLocal的跨服务传递,有没有实现方案?因为分布式项目我可能调用的是下游系统,我想让ThreadLocal中的东西也传递过去,有没有了解过相关技术实现?
- 线程池的相关参数有哪些?
- 如果我现在要根据线程池参数,实现一个具有缓冲能力的线程池,该如何进行设计?
- 这种方案为什么可以起到缓冲的作用,能解释一下吗?
- 用线程池的时候参数你是如何进行设计的,还是说用默认的?
- 进行反问